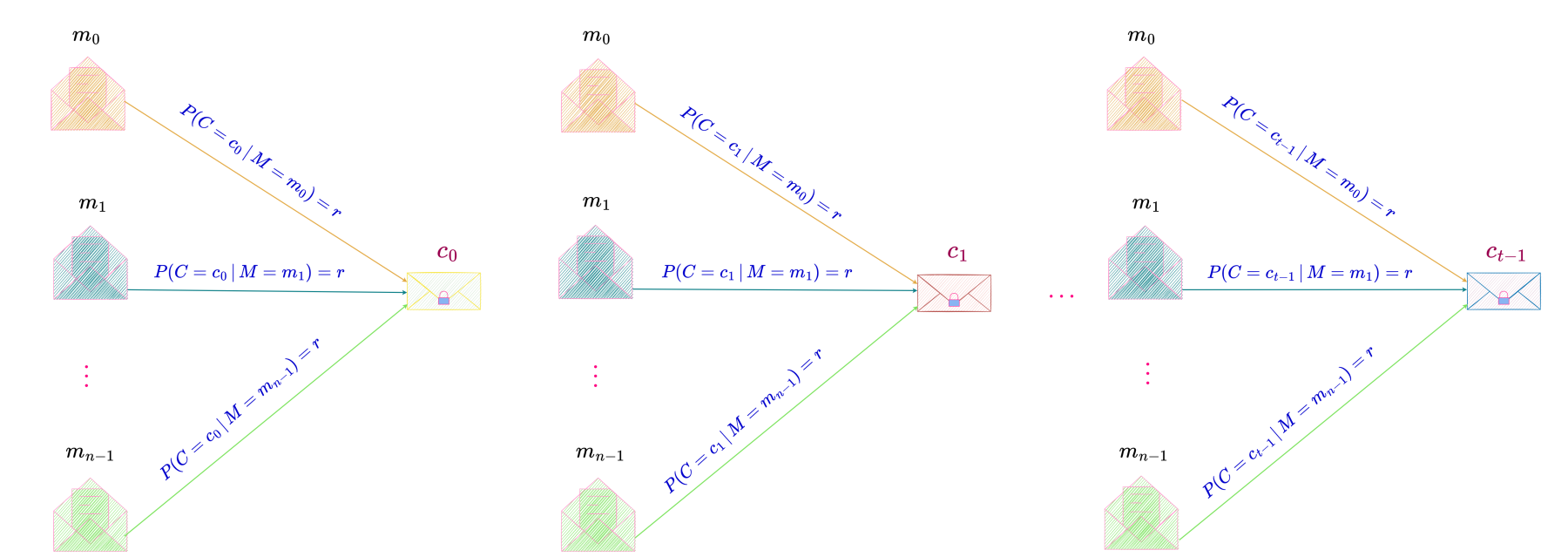
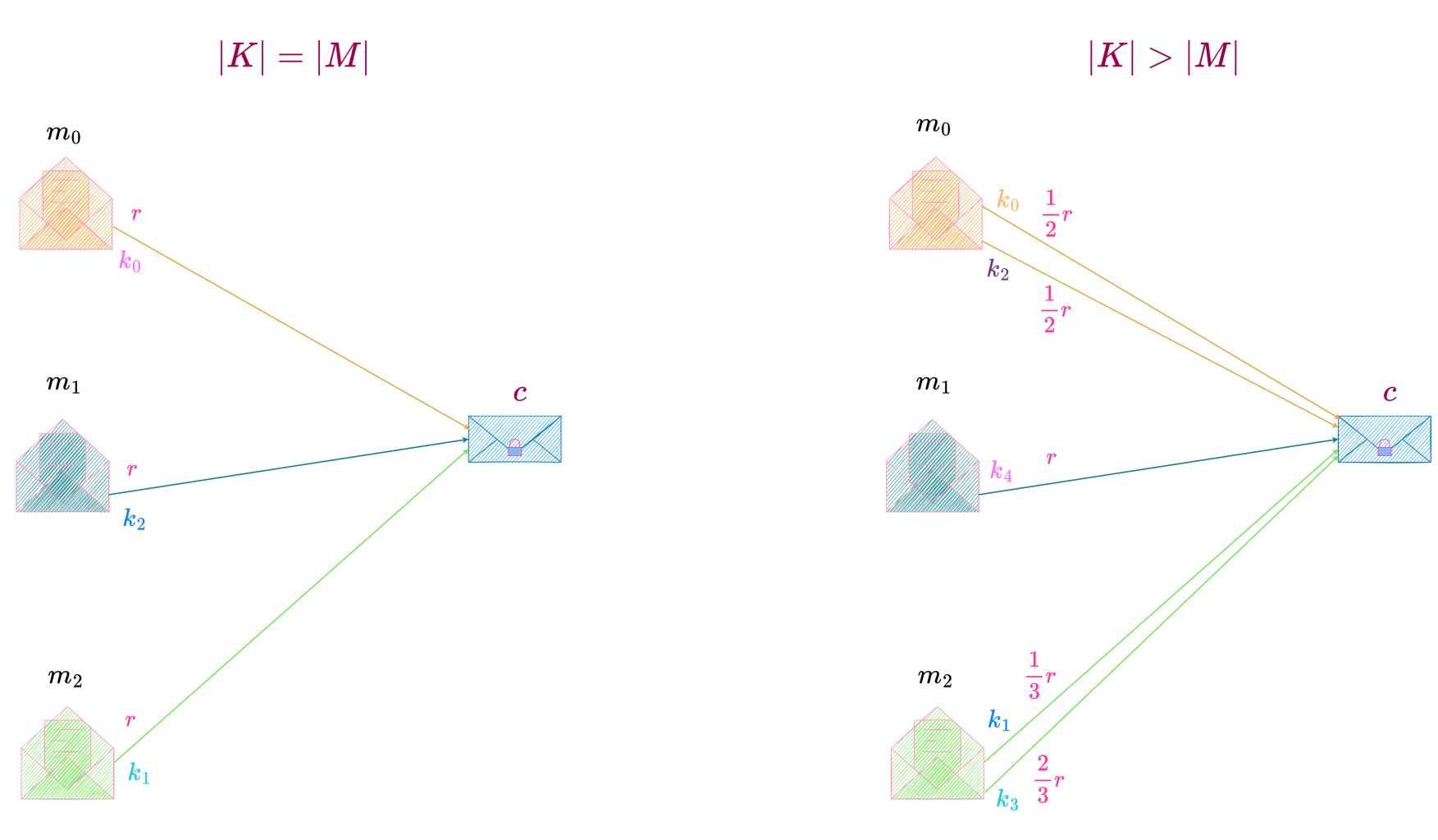
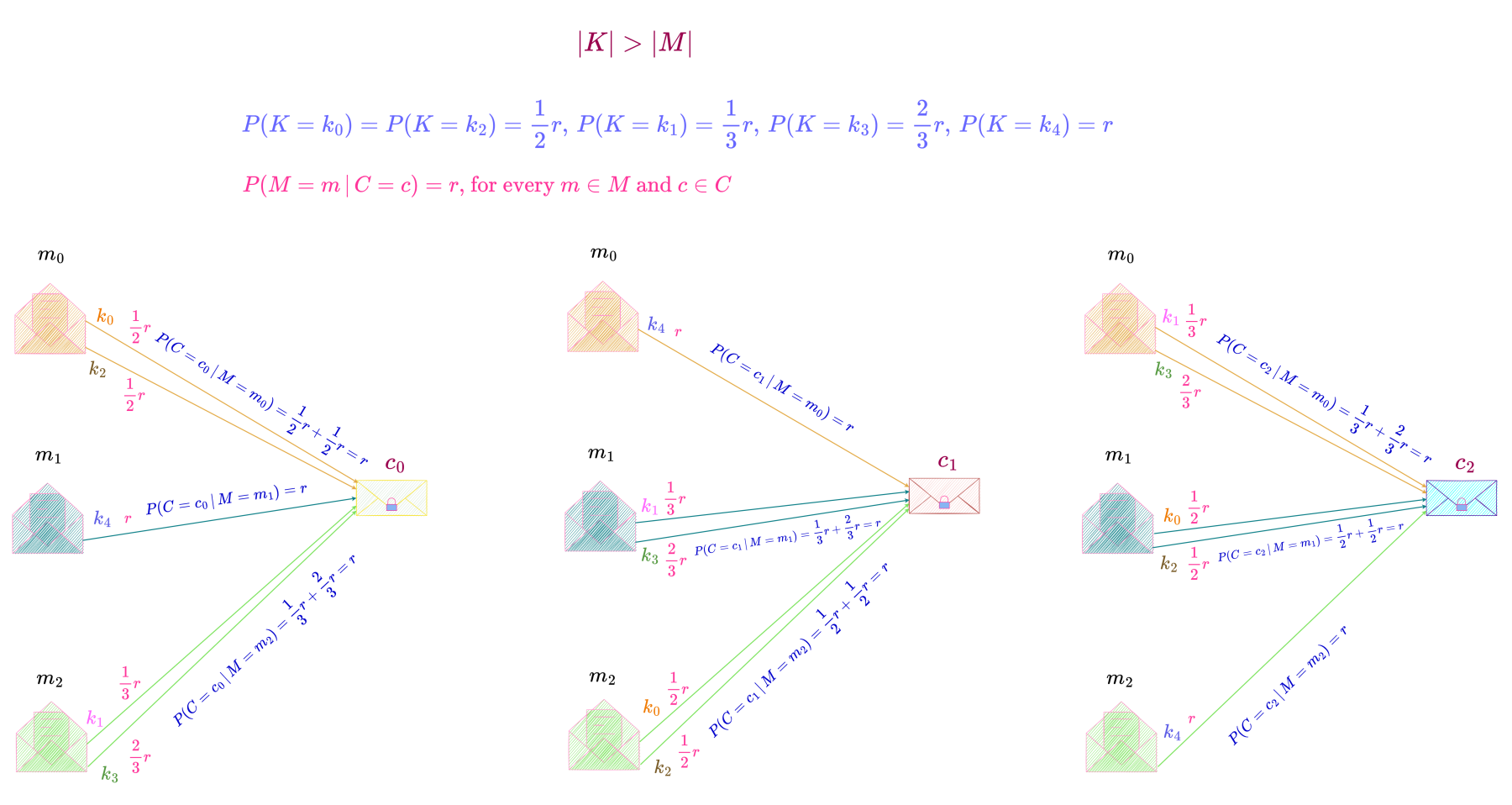
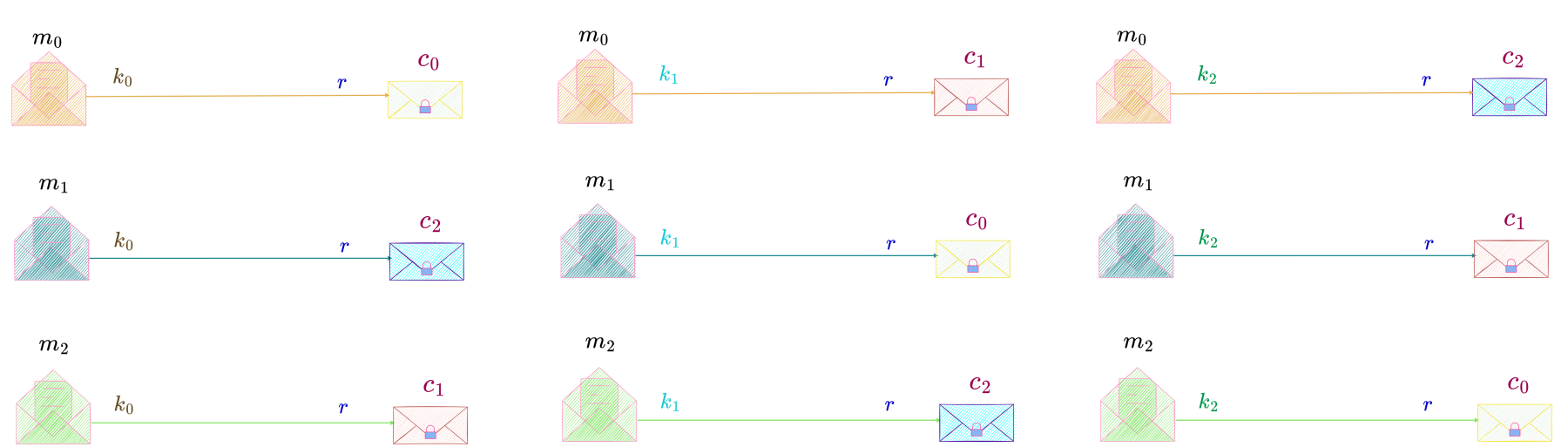
authored by Premmi and Beguène
We will briefly discuss some topics from set theory which we will encounter during our study of number theory and cryptography.
Mathematical Object
A mathematical object is an abstract entity, precisely defined, often in terms of other mathematical objects, and ultimately grounded in a set of axioms—fundamental assumptions that are taken as starting points within a particular mathematical theory.
Unlike physical objects that exist in the real world, mathematical objects exist only in the realm of ideas. This abstract nature is a key characteristic of mathematical objects. A physical chair is a concrete object, while the concept of a chair, which might be studied mathematically in terms of its shape or dimensions, is an abstract mathematical object.
These objects can represent a wide range of mathematical concepts, including:
- Numbers: Integers (\text{e.g.,} -\!2, 0, 5), real numbers (\text{e.g., }\pi, \sqrt{2}), complex numbers (\text{e.g., }2 + 3i).
- Sets: The empty set (\emptyset), the set of natural numbers (\mathbb{N} = \{1, 2, 3, \ldots\}).
- Relations: “less than” (\text{e.g., }4 < 5).
- Functions: e.g., f(x) = x^2.
- Sequences: e.g., 1, 2, 4, 8, \ldots.
- Geometric Objects: Points, lines, planes, triangles, spheres.
- Abstract Structures: Groups, rings, fields.
Mathematical objects are characterized by their properties and by the relationships they have with other mathematical objects. They are the focus of mathematical study, and mathematicians explore and analyze them using the tools of mathematical logic.
While we often use informal language to talk about mathematical objects (e.g., “the number 2"), formal definitions are crucial for rigor. Within a specific mathematical theory, such as set theory, mathematical objects are defined precisely using the language of that theory. This distinction between formal and informal language is not merely a matter of style; it is essential for mathematical rigor and to avoid ambiguity.
Mathematical Theorems and Proofs
Mathematical objects are related to one another through the process of mathematical proof.
Axiom
The process of mathematical proof is central to mathematics. It’s how we establish mathematical truths with certainty. These proofs are ultimately based on a set of fundamental assumptions called axioms.
Axioms are fundamental assumptions that are taken as starting points within a particular mathematical theory. They are not proven within that theory itself, but rather serve as the foundation upon which all proofs within that theory are built. While historically some axioms were considered “self-evident”, modern mathematics emphasizes the role of axioms as postulates—accepted assumptions—rather than necessarily “obvious” truths. For example, the Peano Axioms, while fundamental, are not necessarily “self-evident” in the everyday sense. They are postulates that we accept as the basis for reasoning about natural numbers.
Different mathematical theories have different sets of axioms. For example, the Peano Axioms are a set of axioms that define natural numbers by including axioms that define zero, the successor function, and the principle of mathematical induction. Set theory, on the other hand, is a theory about sets and their properties. It is typically based on the Zermelo-Fraenkel axioms (ZF), which include axioms about the existence of the empty set, pairing, unions, power sets, and so on. These two theories, number theory and set theory, have entirely different sets of axioms because they are about fundamentally different kinds of mathematical objects.
Proof
A proof is a rigorous and logically sound argument that demonstrates the truth of a mathematical statement. These proofs are constructed step-by-step, with each step justified by an axiom, a previously proven theorem, or a rule of logic.
Theorem
A theorem is a mathematical statement that has been proven to be true. Theorems are important because they expand our knowledge of mathematical objects and their relationships. Once a statement has been proven to be a theorem, we can use it as a building block in the proofs of other theorems.
Lemma
A lemma is a preliminary theorem used in the proof of another, typically more significant, theorem.
Corollary
A corollary is a theorem that follows directly (and often easily) from another theorem.
Property
Mathematical objects have characteristics called properties that are fundamental to how we define, classify, reason about and prove theorems about them. A property is a characteristic that some mathematical objects possess. If an object possesses a particular property, then statements about that object based on that property are true.
Properties are often used to classify and distinguish mathematical objects. For instance, a circle is defined as the set of all points equidistant from a given point (its centre). Since this property is not shared by an ellipse, this difference allows us to classify them as distinct shapes.
Similarly, being divisible by 2 is a property of the number 6, classifying it as even and distinguishing it from odd numbers, which lack this property.
Here are further examples of properties for various mathematical objects:
- Numbers: is prime, is positive, is greater than 5, is a perfect square, is rational
- Sets: is finite, is a subset of, is empty, has cardinality n, is infinite
- Functions: is continuous, is differentiable, is linear, is injective (one-to-one), is surjective (onto)
- Geometric figures: is a triangle, is a circle, has an area greater than 12, is a square, is congruent to
For each property, the collection of all objects that satisfy the property is called its extension. For example, the extension of the property “is greater than 5" is the collection of all numbers which are greater than 5.
As we have discussed, mathematical objects are characterized by their properties. But the property “is even” is just a concept—an idea—that exists independently of how we represent it. It’s the idea of being divisible by 2. How do we determine with mathematical rigor whether an object has a particular property? We will do so using predicate—a formal statement that, when applied to an object, is true if and only if that object possesses the property it represents—which will be our next topic of discussion.
Predicate
When we talk about properties informally, we often use natural language. For example, we might say “The number 4 is even.” or “That shape is a triangle.” While these statements are understandable, they express specific instances of properties. Mathematical theorems and proofs are often about all objects of a certain type (e.g., all even numbers, all triangles, all continuous functions). We want to make statements that are universally true within a specific mathematical system. Therefore, for rigorous mathematical reasoning, we need to represent properties in a general and precise way. This is where predicates come in.
Definition
A predicate is a sentence containing one or more variables, each representing a mathematical object. This sentence becomes a proposition—a statement that is either true or false—only when specific values are assigned to those variables. Crucially, predicates serve as formal representations of properties, allowing us to determine whether a given object possesses that property. They act as formal tests or criteria for recognizing instances of the property.
While predicates with a single variable are used to represent properties of individual objects, predicates can also have multiple variables, allowing us to express relationships between objects. We will explore these relationships, called relations, in more detail later.
Truth Set and Universe of Discourse
The collection of objects that, when substituted for the variables in a predicate, makes it a true proposition is called the truth set of the predicate.
To determine the truth set, we must know which objects are available for consideration; that is, we must assume that a universe of discourse has been agreed upon (either explicitly or implicitly through context). Commonly used universes of discourse are the number systems which consist of the natural numbers (\mathbb{N}), integers (\mathbb{Z}), rational numbers (\mathbb{Q}), real numbers (\mathbb{R}), and complex numbers (\mathbb{C}).
With a universe specified, two predicates P(x) and Q(x) are equivalent if they have the same truth set.
For example, the predicates “5x + 7 = 17" and “x = 2" are equivalent predicates in any of the number systems we have mentioned above. On the other hand, “x^2 = 9" and “x = 3" are not equivalent when the universe is \mathbb{Z} because “x = -3" is also a solution to “x^2 = 9". However, they are equivalent when the universe is \mathbb{N} because we only consider positive integers..
Examples
Let’s illustrate how a predicate formalizes the property “evenness”.
Informally, we understand “evenness” as the characteristic of being divisible by 2. However, to work with this concept mathematically, we need a precise and general way to express it. We can use a predicate, often denoted as P(x), where x represents any mathematical object—in this case, an integer. Therefore, the universe of discourse is the collection of all the integers, usually represented as a set, which will be the topic of our next discussion. P(x) represents the sentence “x is divisible by 2”.
Now, P(x) is not a statement about a specific number. It’s a template or a rule that we can apply to any number. When we substitute a specific value for x, the predicate becomes a statement (or proposition) that is either true or false.
For example, if we substitute x = 4, then P(4) becomes the proposition “4 is divisible by 2", which is true; if we substitute x = 5, then P(5) becomes the proposition “5 is divisible by 2", which is false. The truth set of P(x) is the set of all even integers.
The predicate P(x) itself is not true or false. It’s a formal representation of the property of evenness. It provides a precise way to test if a number has that property.
Similarly, the property of “being a triangle” can be represented by a predicate T(s), where s represents any geometric shape. T(s) represents the statement “s is a triangle”. If we substitute a triangle for s, T(s) becomes true. If we substitute a square, T(s) becomes false. Here the universe of discourse is set of all geometric shapes and the truth set of T(s) is the set of all triangles.
Functional Predicate
Among the various types of predicates, there is a special category known as functional predicates.
A functional predicate is a predicate that represents a function. In essence, it’s a way to express a function’s behavior using the language of predicates. A functional predicate, often denoted as F(x, y), expresses the relationship between an input x and its corresponding output y of a function.
The key characteristic of a functional predicate is that for every input x, there is a unique output y that makes the predicate true. This uniqueness is what distinguishes functional predicates from general predicates and allows them to accurately represent functions.
Universe of Discourse and Truth Set
For a functional predicate F(x, y), the Cartesian product X \times Y serves as the universe of discourse, where X is the domain and Y is the codomain of the corresponding function.
The truth set of F(x, y) is the collection of ordered pairs (x, y) chosen from the Cartesian product X \times Y that makes the predicate true. For example, for the functional predicate F(x, y): y = 2x with \mathbb{N} \times \mathbb{N} as the universe of discourse, the truth set includes pairs like (1, 2), (2, 4), (3, 6) and so on. We can see that for any given x value, there is only one possible y value that will make the predicate F(x, y) true.
Definition
A predicate F(x, y) with its universe of discourse as the Cartesian product X \times Y of sets X and Y is a functional predicate if and only if:
- For every x \in X, there exists a y \in Y such that F(x, y) is true.
- For every x \in X, if F(x, y) is true and F(x, z) is true, then y = z.
Examples
The following are some examples of functional predicates:
- Linear Function: The function f(x) = 2x can be expressed as the functional predicate F(x, y): y = 2x.
- If x = 3 and y = 6 then F(3, 6) is true.
- If x = 3 and y = 7 then F(3, 7) is false.
- Quadratic Function: The function f(x) = x² + 1 can be expressed as the functional predicate F(x, y): y = x² + 1.
- If x = 2 and y = 5 then F(2, 5) is true.
- If x = 2 and y = 4 then F(2, 4) is false.
- String Length Function: Let f(s) be a function that returns the length of a string s. This can be expressed as the functional predicate F(s, n): n \text{ is the length of string } s.
- If s = \text{``hello"} and n = 5 then F(\text{``hello"}, 5) is true.
- If s = \text{``hello"} and n = 4 then F(\text{``hello"}, 4) is false.
Connection to Functions
As we have seen in the previous examples, a function can always be expressed as a functional predicate, and conversely, a functional predicate defines a function. The truth set of a functional predicate F(x, y) is the function represented as a set of ordered pairs (x, y) that satisfy the predicate.
We have now explored the concept of functional predicates, which provide rigorous way to define functions using the language of predicates. Functional predicates play a crucial role in the foundations of mathematics, particularly in axiomatic set theory.
The concept of a set is one of the most fundamental concepts in mathematics, which are often defined using predicates. Therefore, we will now discuss sets and how they are defined.
Set
Sets are often considered fundamental building blocks from which many other mathematical objects can be constructed. In this section, we will provide a detailed exposition of what sets are.
A set is defined as a collection of objects that is well-defined. By well-defined, we mean that it is possible to determine unambiguously whether an object is to be included in the set or not.
The concept of a set is very general. While, in principle, the objects in a set can be anything, in mathematics we are primarily interested in sets of mathematical objects. These can be numbers, geometric figures, functions, and so on.
There is no restriction on the number of objects in a set. It can be finite or infinite; it may contain just one object, or even none. Also, there is no requirement for uniformity in the type of object used to construct the set–a perfectly good set might consist of four numbers, two squares and a function.
To deal with all of the sets that arise in mathematics, it is easiest to develop first those general properties common to all sets, and then to apply them in more special situations.
Membership
The objects in the set are called elements or members of the set. The members themselves are said to belong to the set.
To express symbolically that an element x belongs to a set S, we write x \in S.
If x does not belong to S, we write x \notin S.
Equality of Sets
Though sets can be described in different ways, a set is ultimately determined by its members.
For example, if X is the set of solutions of the equation
x^2 -6x + 8 = 0
and Y is the set of even integers between 1 \text{ and } 5, then X \text{ and } Y both have precisely two members, 2 \text{ and } 4. This means that X \text{ and } Y are the same set.
Therefore, we say that two sets are equal if they have the same members.
Equality of two sets S \text{ and } T is expressed in the usual way by S = T, and if S \text{ and } T are not equal, we write S \neq T.
This apparently banal criterion for equality of sets has some interesting consequences, as we shall see shortly.
Defining Sets
Sets are usually denoted by capital letters in italic, such as X, Y, Z and lower-case letters such as x, y, z to represent numbers and other objects that are individual elements, rather than sets.
There are three ways of describing sets, namely, the Roster notation, semantic description and the set-builder notation.
Roster Notation
Roster or enumeration notation defines a set by listing its elements. The elements are listed between curly braces and separated by commas.
For example, S = \{1, 4, 7, 11\} means that S.is the set who members are the numbers 1, 4, 7, 11 and only these.
The basic relation in set theory is that of elementhood, or membership i.e., in a set all that matters is whether an element is in it or not; thus, the order or repetition of elements in the roster notation is irrelevant. For example, \{1, 2, 3\} \text{ and } \{3, 2, 3, 1\} represent the same set.
For sets with many elements, where the elements follow some implicit pattern, the list of elements can be abbreviated using an ellipsis, denoted by ‘…’. For example, the set of first hundred even numbers may be specified in roster notation as \{2, 4, 6, \ldots, 200\}.
To describe an infinite set in roster notation, an ellipsis is placed at the end of the list or at both ends to indicate that the list continues forever. For example, in roster notation, the set of positive integers is represented as \{1, 2, 3, \ldots\} and the set of integers is represented as \{\ldots,-3,-2,-1,0,1, 2, 3, \ldots\}.
When specifying a set, it may not be convenient, or even possible, to write down a complete list of all the members. For example, the set of prime numbers is better described precisely by that phrase, rather than by the list \{2, 3, 5, 7, 11, 13, 17, 19, \ldots\}. Indicating a few terms of an infinite set in this manner might be open to misinterpretation since the elements inside the braces need not be in any specific order. So this list may also be written as \{13, 17, 19, 2, 3, 7, 11, 5, \ldots\}. How could we be sure that this is the set of all primes?
As we saw with the set of prime numbers, roster notation can be inadequate for describing infinite sets or sets with complex membership criteria. Semantic description which we will discuss next provides a way to overcome this limitation.
Semantic Description
A semantic description of a set defines the set by using a sentence to specify the properties of objects contained in the set. This method of description does not list the elements of the set explicitly but rather provides a clear and unambiguous description of what the elements are or how they are determined.
For example, “Let X be the set of all the prime numbers.” is a valid semantic description. This clearly defines the set without listing all its elements.
We’ve seen how the semantic description describes a set as a collection of objects that share some common properties. As we have already discussed, these properties can be formalized using a mathematical predicate–-statement about an object that is either true or false depending on whether the object has the properties described by the predicate. Predicates provide the mathematical rigor needed to define the properties of objects concisely and precisely. Set-builder notation then uses these predicates to define sets in a very clear and compact way which will be our next topic of discussion.
Set-Builder Notation
A Formal Language for Defining Sets
While we can describe sets using roster notation (\text{e.g.,} \{1, 2, 3, 4\}) or semantic description (e.g., “the set of all prime numbers”), set-builder notation offers a precise and unambiguous way to define sets based on the properties their elements must satisfy.
Suppose we want to define the set of even numbers. We could start with the set of all integers and “filter” this set to keep only the even numbers. But how do we express this filtering process precisely and concisely? We do so using predicates—formal statements that are either true or false for a given object, depending on whether or not the object satisfies the property represented by the predicate. A predicate, therefore, acts as our “filter”, specifying the property an object must have to be included in our new set. Set-builder notation allows us to formally define sets based on these predicates, which, in turn, represent the properties of their elements.
A set S described in set-builder notation has the form
S = \big\{x \in X\,|\, P(x)\big\}Let’s break down this notation:
- \{\,\, \ldots \,\, \}: The curly braces denote a set. They enclose the description of the set’s elements.
- x \in X: This part specifies that we are considering elements x that belong to a pre-existing set X. X is often called the parent set, universal set or universe of discourse. It defines the pool of potential elements from which we will select those that meet our criteria.
- \big|: This vertical bar is read as “such that” or “for which.” It separates the generic element x from the condition P(x) it must satisfy. We can also use “:” instead of the vertical bar.
- P(x): This is a predicate—a statement that can be either true or false for a given x. It expresses the property that elements of the new set must possess. It’s the “filter” that determines which elements from X are to be included in the set S.
In this notation, the description should be read as “S is the set of all x that are elements of X such that P(x) is true.”
Examples
Following are some examples of defining sets using set-builder notation:
- Even Integers: Let \mathbb{Z} represent the set of all integers (our universe of discourse). We can define the set of even integers E as:
E = \{x \in \mathbb{Z} \,|\, x \text{ is divisible by } 2\}. This reads as “E is the set of all x that are elements of \mathbb{Z} such that x is divisible by 2." The predicate P(x) here is “x is divisible by 2". It selects only those integers that are divisible by 2, effectively “filtering” the integers to get the even integers. - Squares of Natural Numbers: Let \mathbb{N} represent the set of natural numbers (our universe of discourse). The set of perfect squares S within the natural numbers can be defined as:
S = \{x \in \mathbb{N} \,|\, \text{there exists a } y \in \mathbb{N} \text{ such that } x = y^2\}. This reads as “S is the set of all x that are elements of \mathbb{N} such that there exists a y that is also an element of \mathbb{N} for which x equals y squared.” This example demonstrates how set-builder notation can express more complex conditions using quantifiers (like “there exists”, denoted by \exists). The predicate here is “there exists a y \in \mathbb{N} \text{ such that } x = y^2".
However, it’s important to note that this predicate, as written, is a tautology for any y. This means that for any x that is a perfect square, there will always be exactly one y in \mathbb{N} that satisfies x = y^2. While this representation is technically correct, it’s not the most efficient or intuitive. We will subsequently discuss better ways to represent this set using functions, which will lead to a more concise and clear notation. - Prime Numbers: Let \mathbb{N} be our universe of discourse again. The set of prime numbers P can be defined as:
P = \{ p \in \mathbb{N} \,|\, p > 1 \text{ and for all } n \in \mathbb{N}, \text{if } n \text{ divides } p, \text{ then } n = 1 \text{ or } n = p\}. This example shows how to express a more complex mathematical property (primality) using set-builder notation. - A More Abstract Example: Let X be any set. We can define a set Y containing all elements that are not equal to a specific element z in X as:
Y = \{x \in X \,|\, x \neq z\}. This reads as “Y is the set of all x that are elements of X such that x is not equal to z.” - Bounded Set of Reals: Let \mathbb{R} be the set of real numbers. We can define the set of real numbers between 0 \text{ and } 1 (inclusive) as:
\{x \in \mathbb{R} \,|\, 0 \leq x \leq 1\}.
More Complex Expressions: Using Functions
In our previous examples of set-builder notation, we primarily saw cases where the elements of the set were directly taken from the parent set (also referred to as the universe of discourse). However, set-builder notation is much more flexible. We can also define sets where the elements are some transformations (represented as functions) of the elements from the parent set, and these resulting elements can be further filtered if required based on specific properties.We will explore functions in greater depth later, but for now, it’s important to understand that the left side of set-builder notation can represent a function of x denoted by f(x).
Consider the example of the set of perfect squares within the natural numbers:
S = \big\{x \in \mathbb{N} \,|\, \text{there exists a } y \in \mathbb{N} \text{ such that } x = y^2\big\}This notation expresses the set of perfect squares, but it can be rewritten using a function to make it more concise.
To express the set of perfect squares in set-builder notation using functions, we can define the function f(y) as f(y) = y^2 and the universe of discourse X as X = \mathbb{N}. Then, the set of perfect squares can be written in set-builder notation as:
S = \big\{y^2 \,|\, y \in \mathbb{N}\big\}This reads as “the set of all y squared such that y is a natural number.”
This example demonstrates how the function form of set-builder notation can be used to define sets where the elements are functions of other elements.
A set S described in set-builder notation has the general form:
S = \big\{f(x) \,|\, x \in X \text{ and } P(x)\big\}Here:
- f(x) is a function that takes an element x as input and produces a value as output.
- x \in X specifies that x belongs to a pre-existing set X (the universe of discourse).
- P(x) is a predicate that specifies a condition that x must satisfy. This part is optional. If no additional condition is needed, it can be omitted.
Examples
Following are some examples of defining sets using the function form of set-builder notation:
- Even Integers:
- Let
f(x) = 2x(the function) andX = \mathbb{Z}(the universe of discourse). - The set of even integers can be defined as
\{2x \,|\, x \in \mathbb{Z}\}. - This reads as “the set of all 2x such that x is an integer.” Here, P(x) is omitted.
- Let
- Odd Integers:
- Let
f(x) = 2x + 1(the function) andX = \mathbb{Z}(the universe of discourse). - The set of odd integers can be defined as
\{2x + 1 \,|\, x \in \mathbb{Z}\}. - This reads as “the set of all 2x plus one such that x is an integer.” Here, P(x) is omitted.
- Let
- Squares of positive real numbers greater than 3:
- Let
f(x) = x^2,X = \mathbb{R}andP(x)bex > 3. - The set of squares of real numbers greater than 3 can be defined as
\{x^2 \,|\, x \in \mathbb{R} \text{ and } x > 3\}. - This reads as “the set of all x squared such that x is a real number and x is greater than 3". Here P(x) \text{ is } x > 3.
- Let
- Rational Numbers:
- Let
f(p, q) = p/q(the function of two variables),X = \mathbb{Z}, Y = \mathbb{Z}(universes of discourse) andP(q)beq \neq 0. - The set of rational numbers, \mathbb{Q}, can be defined as
\{p/q \,|\, p,q \in \mathbb{Z} \text{ and } q \neq 0\}. - This reads as “the set of all p divided by q such that p is an integer and q is an integer not equal to 0". Here P(q) \text{ is } q \neq 0.
When defining sets using functions in set-builder notation, the function doesn’t always have to have a single input. For example, to define the set of rational numbers \mathbb{Q}, we use the function f(p, q) = p/q, where p and q are integers. This function takes two inputs and produces a single output, which is the ratio of p and q. This is related to the concept of a binary operation, which we will discuss in more detail later.
- Let
- Ordered Pairs Representing Odd Integers
- Let
f(t) = (t, 2t + 1)(the function creating ordered pairs) andX = \mathbb{Z}(the universe of discourse). - The set of ordered pairs representing odd integers can be defined as
\big\{(t, 2t + 1) \,|\, t \in \mathbb{Z}\big\}. - This reads as “the set of all ordered pairs (t, 2t + 1) such that t is an integer.” Here, P(t) is omitted.
This example demonstrates how set-builder notation can be used to create sets of ordered pairs, representing function mappings. Here, the function f(t) = (t, 2t + 1) takes an integer t and produces an ordered pair where the first element is t and the second element is 2t + 1, which is an odd integer. The ordered pair provides a specific association, pairing each integer t with its corresponding odd integer 2t + 1. For instance, when t = 0, the pair (0, 1) associates 0 with 1; when t = 1, the pair (1, 3) associates 1 with 3, and so on. This set visually represents the relationship between integers and odd integers as a set of pairs, which is a fundamental concept in defining functions as sets of ordered pairs.
- Let
These examples illustrate the flexibility and power of set-builder notation. Set-builder notation allows us to define sets precisely and concisely either by selecting elements based on their specific properties from a pre-existing set (referred to as the universe of discourse) or by creating elements from a pre-existing set by transforming its elements using functions and optionally, further selecting from these transformed elements those that satisfy some specific properties. The universe of discourse could be a familiar number system or a more abstract set. The key is always to identify the parent set (also called the universe of discourse) and the criteria for membership in the new set, which may be specified by a predicate alone or by a function and an optional predicate.
Proving Equality of Sets Defined by Set-Builder Notation
As we have already discussed, two sets are equal if and only if they contain the same elements. When sets are defined using set-builder notation, their equality hinges on the equivalence of their defining rules, which encompass predicates, functions (if present) and domain specifiers (universes of discourse).
We will now discuss how to determine the equality of these sets whose definition encompasses predicates, functions or both.
Sets Defined by Predicates
Specifically, given sets X \text{ and } Y, and predicates P(x) \text{ and } Q(x), we have:
\big\{x ∈ X \,|\, P(x)\} = \{x ∈ Y \,|\, Q(x)\big\}\text{ if and only if}(\forall t)[(t \in X \land P(t)) \iff (t \in Y \land Q(t))]
This means that the sets \{x \in X \,|\, P(x)\} and \{x \in Y \,|\, Q(x)\}, defined by the predicates P(x) and Q(x) on sets X and Y respectively, are equal if and only if for any element t, the combined conditions of t belonging to X and satisfying P(t) are logically equivalent to the combined conditions of t belonging to Y and satisfying Q(t).
Therefore, to prove the equality of two sets defined by set-builder notation using predicates, it is sufficient to demonstrate the equivalence of their defining rules, including both the predicates and the domain qualifiers (universes of discourse).
Example
Consider the sets \{x \in \mathbb{R} \,|\, x^2 = 1\} and \{x \in \mathbb{Q} \,|\, |x| = 1\}.
These sets are equal because the two rule predicates are logically equivalent as shown below.
(x \in \mathbb{R} \wedge x^2 = 1) \iff (x \in \mathbb{Q} ∧ |x| = 1)This equivalence holds because, for any real number x, x^2 = 1 if and only if x is a rational number with |x| = 1. In particular, both sets are equal to the set \{-1, 1\}.
Sets Defined by Functions
Given two functions f(x) \text{ and } g(y) with sets X \text{ and } Y as their respective domains and predicates P(x) \text{ and } Q(y) with X \text{ and } Y as their respective universes of discourse, we have:
\big\{f(x) \,|\, x \in X \wedge P(x) \big\} = \big\{g(y) \,|\, y \in Y \wedge Q(y) \big\}\text{if and only if}(\forall z \in Z) \big[(\exist x \in X) (f(x) = z \wedge P(x)) \iff (\exist y \in Y) (g(y) = z \wedge Q(y))\big]
where Z is a set that contains all possible output values from f(x) \text{ and } g(y) i.e., Z is a set that includes the ranges of both functions.
This means that for any element z \in Z, z is an element of \big\{f(x) \,|\, x \in X \wedge P(x) \big\} if and only if z is an element of \big\{g(y) \,|\, y \in Y \wedge Q(y) \big\}.
Example
Consider two sets A \text{ and} B defined as follows:
- A = \{(2x + 1)^2 \,|\, x \in \{0, 1, 2\}\}
- B = \{8y + 1 \,|\, y \in \{0, 1, 3\}\}
Let us determine the elements of sets A \text{ and } B.
- Set A
- x = 0: (2(0) + 1)² = 1² = 1
- x = 1: (2(1) + 1)² = 3² = 9
- x = 2: (2(2) + 1)² = 5² = 25
- Therefore, A = \{1, 9, 25\}
- Set B
- y = 0: 8(0) + 1 = 1
- y = 1: 8(1) + 1 = 9
- y = 3: 8(3) + 1 = 25
- Therefore, B = \{1, 9, 25\}
We can see that even though the functions used to define A \text{ and } B are different, and the domains are slightly different, the resulting sets are identical i.e., A = B.
Conclusion
Predicate Equivalence
When sets are defined by predicates alone, their equality requires the logical equivalence of the predicates and domain specifiers.
Function Equivalence
When sets are defined by functions, their equality requires that for every possible output value z (within the combined range of the functions), z is in one set if and only if it is in the other. This ensures that the sets contain the same elements, even when the functions or universes of discourse are different.
We’ve seen how set-builder notation allows us to define sets and prove their equality, using both predicates and functions. Now, it’s time to examine the axiomatic basis that makes this definition possible. The Axiom of Separation ensures the validity of set definitions using predicates, and the Axiom of Replacement does the same for sets defined through functions.
The Theoretical Foundation: The Axiom of Separation
Now that we have seen how set-builder notation works, it’s important to understand its theoretical basis. This notation is not just a convenient shorthand; it’s deeply rooted in the foundational principles of axiomatic set theory, specifically the Axiom of Separation. This axiom ensures that we can define new sets by selecting elements from existing sets using predicates, without running into logical contradictions like Russell’s Paradox.
Russell’s Paradox highlights the dangers of unrestricted set formation. It considers the set R defined as “the set of all sets that do not contain themselves as elements.” This definition is based on the predicate “x is a set and x \notin x", which, when used to define R, leads to a contradiction as explained below.
The Predicate: The core of Russell’s Paradox is the predicate P(x), which is defined as: P(x) = x \text{ is a set and } x \notin x. That is, P(x) is true if and only if x is a set and x is not an element of itself.
Defining the Set R: Russell’s set R is then defined using set-builder notation based on this predicate: R = \{x \,|\, P(x)\} or equivalently, \{x \,|\, x \text{ is a set and } x \notin x\}. This reads as “R is the set of all x such that x is a set and x is not an element of itself.”
The Paradox: The paradox arises when we ask: Is R an element of itself? In other words, is R \in R?
- Case 1: Assume R \in R. If R is an element of itself, then by the definition of R \,(\text{and the predicate } P(x)\!), R must not be an element of itself. This is a contradiction.
- Case 2: Assume R \notin R. If R is not an element of itself, then R satisfies the predicate P(x) (because R is a set and R \notin R). Therefore, by the definition of R, R must be an element of itself. This is also a contradiction.
The Problem: Since both R \in R and R \notin R lead to contradictions, the very definition of R is problematic and the assumption that R is a set is not valid. It shows that we cannot define sets completely arbitrarily. The unrestricted use of predicates to define sets can lead to inconsistencies.
Why the Axiom of Separation Helps:
The Axiom of Separation avoids this paradox by restricting set formation. Instead of allowing us to define sets using any predicate, it requires us to start with an existing set X and then use a predicate to select elements from this set X to form a new set . This prevents us from creating sets like R that attempt to include “all sets” without a clearly defined parent set or universe of discourse, which is what leads to the self-referential paradox. The “x \in X" part of the set-builder notation in conjunction with the Axiom of Separation is what prevents the problematic self-reference. We are always building sets from existing sets, never creating sets “from thin air” that could lead to these kinds of contradictions. This is the key idea behind the Axiom of Separation, which states:
For any set X and any predicate P(x), there exists a set Y such that for all x, x \in Y if and only if (x ∈ X \text{ and } P(x)).
In simpler terms: Given a set X (often called the “parent set” or “universe of discourse”) and a predicate P(x) which expresses a property, we can form a new set Y containing precisely those elements of X that satisfy P(x). This axiom is crucial because it emphasizes that we always form new sets by selecting elements from existing sets. We don’t create sets from nothing, which is essential for avoiding paradoxes like Russell’s Paradox.
Additionally, this axiom highlights the connection between sets and predicates. For instance, given any set that is defined by selecting elements from an existing set, we can define a predicate that determines membership in this set. This demonstrates that any set defined from an existing set can be represented by a predicate. Thinking about this equivalence naturally leads to a more abstract question about the nature of mathematical objects themselves. Are sets primary, and properties merely ways to delineate them, or do the underlying properties hold a more fundamental status? This is a rich area of philosophical debate within mathematics, though we will not delve into it further here.
This grounding in the Axiom of Separation provides a solid foundation for set-builder notation, ensuring its consistency and reliability as a tool for defining sets in mathematics. It should be noted that the Axiom of Separation is a cornerstone of Zermelo-Fraenkel set theory (ZFC), the most commonly used foundation for mathematics. It’s worth noting that other axiomatic set theories exist, some of which handle the concept of sets and potential paradoxes in different ways.
Axiom of Replacement
It is important to note that the Axiom of Separation, as stated, primarily addresses the creation of new sets from existing sets based on predicates. However, when using functions within set-builder notation, an additional foundational principle comes into play: the Axiom of Replacement.
The Axiom of Replacement asserts that if F(x, y) is a functional predicate (meaning that for every x, there is a unique y such that F(x, y) is true), and X is a set, then there exists a set Y such that for every x \in X, there is a y \in Y such that F(x, y) is true. In simpler terms, this axiom allows us to create a new set by applying a function to each element of an existing set.
Therefore, when using functions in set-builder notation, we are implicitly utilizing both the Axiom of Replacement and the Axiom of Separation. First, the Axiom of Replacement guarantees the existence of a set containing the transformed elements resulting from applying a function f(x) to the elements of the initial set X. Subsequently, the Axiom of Separation allows us to filter (if required) these transformed elements based on a predicate P(f(x)), creating the final set as defined by the set-builder notation.
In essence, the Axiom of Replacement handles the function application aspect, while the Axiom of Separation handles the filtering based on predicates. This dual application of axioms provides the complete theoretical foundation for defining sets using functions and predicates within set-builder notation.
Our discussion of set-builder notation and its axiomatic foundations, focused on creating sets from existing sets. We will now discuss in detail these sets which are referred to as subsets.
Subsets
A set X is a subset of a set Y, written X \subset Y, if and only if every element of X is an element of Y.
If X is a subset of a set Y, we can also express this relationship as Y \supset X, indicating that Y is a superset of X.
For example, the set of positive integers \mathbb{Z}^+, is a subset of the set of integers \mathbb{Z} i.e., \mathbb{Z}^+ \subset \mathbb{Z}. Since every positive integer is also an integer, it follows that every element of \mathbb{Z}^+ is also an element of \mathbb{Z}. Thus, we can also write \mathbb{Z} \supset \mathbb{Z}^+ and refer to \mathbb{Z} as a superset of \mathbb{Z}^+.
Proving Equality of Sets
Sets are defined by their elements, so intuitively, two sets are equal if they contain exactly the same elements. However, while doing mathematical proofs, this insight does not directly provide a methodology for showing that two sets are equal. Therefore, to prove the equality of two sets, we take recourse to the concept of subsets.
Any two sets X \text{ and } Y are equal if they contain exactly the same elements. If sets X \text{ and } Y contain the same elements, then every element of set X is an element of set Y and every element of Y is also an element of X i.e., X \subset Y and Y \subset X. Therefore, if X \text{ and } Y are to be equal as sets, then X \subset Y and Y \subset X. Thus, in a proof, to show that X = Y, we must show that X \subset Y and Y \subset X.
The Empty Set
The most basic set is the collection of no objects. This set is called the empty set or null set and is denoted by \varnothing \text{ or } \{\} to indicate that it contains no elements.
From the definition of subset, it follows that the empty set \varnothing is a subset of set S if x \in \varnothing implies x \in S. Since the empty set contains no elements, the conditional statement “if x \in \varnothing implies x \in S” is vacuously true. Therefore, the empty set \varnothing is a subset of every set S i.e., \varnothing \subset S, for every set S.
Unordered Pair
Marie has two pens, one in red and another in yellow. If she is asked to list the colors of the pens she has, she can either list them as \{\text{red, yellow}\} or \{\text{yellow, red}\}. The order she lists them doesn’t matter since both the lists convey the same information. Such a pair where the order in which the elements are listed is irrelevant is called an unordered pair.
Definition
An unordered pair is a set of the form \{x, y\}, i.e., a set having two elements x \text{ and } y such that,
\{x, y\} = \{y, x\} \text{ and } x \neq y.
An unordered pair is a finite set of cardinality 2.
Unordered n-tuple
Suppose instead of 2 pens, Marie has 10 pens each of a different color. How would she list the colors of the 10 pens? The mathematical structure she would now use is called an unordered n-tuple.
More generally, the concept of unordered pair can be extended to a set consisting of more than 2 elements i.e., one consisting of n elements, where n is some positive integer.
An unordered n-tuple is a set of the form \{x_1, x_2, \ldots, x_n\} i.e., a set consisting of n distinct elements where the order in which the elements appear in the set is insignificant.
Ordered Pair
Marie takes two exams, one in English and another in Mathematics. When she is asked to list her scores in English and Mathematics, the order in which she lists them matters unless she got the same score in both the exams. The mathematical structure which Marie will now use is called an ordered pair.
Definition
An ordered pair (x, y) is a pair of mathematical objects where the order in which the objects appear in the pair is significant.
That is, in general (x, y) \neq (y, x); (x, y) = (y, x) if and only if x = y.
In the ordered pair (x, y), the object x is called the first entry and the object y, the second entry of the pair. Alternatively, the objects are also referred to as first and second components, first and second coordinates or the left and right projections of the ordered pair.
Cartesian products and binary relations are defined in terms of ordered pairs.
The Cartesian product of two sets X \text{ and } Y is the set of all ordered pairs whose first entry is in set X and whose second entry is in set Y\!\!, and is written as X \times Y.
A binary relation, R, between sets X \text{ and } Y is a subset of X \times Y, i.e., R \subseteq X \times Y.
Defining property of an ordered pair
For any two ordered pairs, (x, y) \text{ and } (u, v), the characteristic (or defining) property of the ordered pair is
(x, y) = (u, v) \text{ if and only if } x = u \text{ and } y = vThat is, the ordered pair (x, y) should be defined in such a way that the above relation holds good. Any definition that has this property will do.
We will next construct a definition of an ordered pair such that it satisfies this property.
Defining the ordered pair using set theory
Since we believe that set theory is the foundation of mathematics, where possible, we will always define mathematical objects as sets. Hence, we will define an ordered pair as a set. We will construct a set-theoretic definition of the ordered pair and prove that this definition satisfies the characteristic property of the ordered pair.
Set-theoretic definition of an ordered pair
The standard set-theoretic definition of the ordered pair (x, y) is, (x, y) := \{\{x\}, \{x, y\}\}.
It should be noted that this definition is valid even when the first and second entries of the ordered pair are identical. That is,
(x, x) = \{\{x\}, \{x, x\}\} = \{\{x\}, \{x\}\} = \{\{x\}\}.
The definition of ordered pair satisfies the characteristic property of the ordered pair
We have to prove that the definition of ordered pair satisfies the characteristic property of the ordered pair, namely,
(x, y) = (u, v) \text{ if and only if } x = u \text{ and } y = vwhere (x, y) \text{ and } (u, v) are ordered pairs.
Proof:
First, we will assume that x = u \text{ and } y = v and prove that (x, y) = (u, v) under this assumption.
By definition,
(x, y) = \{\{x\}, \{x, y\}\}.
Since x = u \text{ and } y = v,
(x, y) = \{\{x\}, \{x, y\}\} = \{\{u\}, \{u, v\}\} = (u, v). (by definition of ordered pair)
Next, we will prove that x = u \text{ and } y = v under the assumption (x, y) = (u, v).
Either x = y \text{ or } x \neq y. We will do the proof for each of these cases.
When x = y :
(x, y) = \{\{x\}, \{x, y\}\} = \{\{x\}, \{x, x\}\} = \{\{x\}, \{x\}\} = \{\{x\}\}.
\{\{u\}, \{u, v\}\} = (u, v) = (x, y) = \{\{x\}\}.
This implies that \{u\} = \{u, v\} = \{x\} so that \{\{u\}, \{u, v\}\} = \{\{x\}, \{x\}\} = \{\{x\}\}.
Since \{u\} = \{x\}, it implies that x = u.
Also, since \{u, v\} = \{x\} and x = u, it must be the case that x = v so that \{u, v\} = \{x, x\} = \{x\}.
We have so far proved that x = u \text{ and } x = v.
By our hypothesis, x = y. Therefore, y = v.
Thus we have proved that, for the case x = y, if (x, y) = (u, v) then x = u \text{ and } y = v.
When x \neq y :
(x, y) = (u, v) implies \{\{x\}, \{x, y\}\} = \{\{u\}, \{u, v\}\} (by definition of ordered pair).
Suppose \{u, v\} = \{x\}. This implies that u = v = x so that \{u, v\} = \{x, x\} = \{x\}.
Consequently, \{\{u\}, \{u, v\}\} = \{\{x\}, \{x, x\}\} = \{\{x\}, \{x\}\} = \{\{x\}\}.
Since \{\{x\}, \{x, y\}\} = \{\{u\}, \{u, v\}\} and \{\{u\}, \{u, v\}\} = \{\{x\}\}, \{\{x\}, \{x, y\}\} = \{\{x\}\}.
If \{\{x\}, \{x, y\}\} = \{\{x\}\} then x = y so that \{\{x\}, \{x, y\}\} = \{\{x\}, \{x, x\}\} = \{\{x\}, \{x\}\} = \{\{x\}\}.
But this contradicts our assumption that x \neq y.
Consequently, \{u, v\} \neq \{x\}.
Suppose \{u\} = \{x, y\}. Then u = x = y so that \{u\} = \{x, y\} becomes \{x\} = \{x, x\} = \{x\}.
But this result contradicts our assumption that x \neq y.
Hence \{u\} \neq \{x, y\}.
Therefore, \{x\} = \{u\}, which implies that x = u and \{x, y\} = \{u, v\}.
If y = u then x = y which contradicts our hypothesis that x \neq y. Hence, y = v.
We have thus proved that if (x, y) = (u, v) then x = u \text{ and } y = v.
We have shown that our definition of ordered pair holds good.
That is, (x, y) := \{\{x\}, \{x, y\}\} satisfies the defining property of an ordered pair, namely,
(x, y) = (u, v) \leftrightarrow (x = u) \wedge (y = v).
This definition of ordered pair adequately embodies the notion of order because (x, y) = (y, x) is false unless x = y.
Tuple
A tuple is a finite enumerated collection of mathematical objects in which repetitions are allowed and order matters. The mathematical objects in a tuple are referred to as the elements of the tuple.
An n-tuple is a tuple of n elements, where n is a non-negative integer.
There is only one 0\text{-tuple}, called the empty tuple. A 1\text{-tuple} is called a singleton, a 2\text{-tuple}, an ordered pair and a 3\text{-tuple}, a triple.
Tuples are usually written by listing the elements within parenthesis and the elements are separated from one another by a comma and a space; for example, (7, 8, 9) denotes a 3\text{-tuple} otherwise called a triple. Sometimes instead of parenthesis, a square or angle brackets are also used to enclose the elements of a tuple. For example, \big[7, 8, 9\big] and \big<7, 8, 9\big> are valid representations of tuples.
Defining properties of an n-tuple
Two n\text{-}tuples (x_1, x_2, \ldots, x_n) and (y_1, y_2, \ldots, y_n) are equal if and only if x_1 = y_1, x_2 = y_2, \ldots, x_n = y_n.
Consequently, a tuple differs from a set in the following ways :
- A tuple may contain multiple instances of the same element, so tuple (4, 5, 6, 6, 7) \neq (4, 5, 6, 7); but set \{4, 5, 6, 6, 7\} = \{4, 5, 6, 7\}.
- Tuple elements are ordered. Tuple (4, 5, 6) \neq (6, 5, 4) but set \{4, 5, 6\} = \{6, 5, 4\}.
- A tuple has a finite number of elements while a set may have an infinite number of elements, for example, the set of integers.
Definition of n-tuple
There are several definitions of tuples that satisfy the properties enumerated above. However, since we have already defined the notion of an ordered pair, we will define an n\text{-}tuple recursively by starting from an ordered pair. An n\text{-}tuple can be viewed as an ordered pair with its first element corresponding to the first element of the ordered pair and its remaining n - 1 elements corresponding to the second element of the ordered pair. This definition can then be recursively applied to the (n - 1)\text{-}tuple.
N-tuple defined as a nested ordered pair
The following is a way to model tuples in Set Theory as nested ordered pairs :
- The 0\text{-}tuple (i.e., the empty tuple) is represented by the empty set \emptyset.
- An n\text{-}tuple with n > 0 can be defined as an ordered pair of its first entry and an (n-1)\text{-}tuple which contains the empty set, \emptyset, when n = 1 and the remaining entries when n > 1. That is,
(x_1, x_2, x_3, \ldots, x_n) = (x_1, (x_2, x_3, \ldots, x_n))
This definition can be applied recursively to the (n-1)\text{-}tuple as follows :
(x_1, x_2, x_3, \ldots, x_n) = (x_1, (x_2, (x_3, (\ldots, (x_n, \emptyset) \dots)))).
For example,
(4, 5, 6) = (4, (5,6)) = (4, (5, (6, \emptyset)))
An alternate way to define an n\text{-}tuple as a nested ordered pair is as follows :
- The 0\text{-}tuple (i.e., the empty tuple) is represented by the empty set \emptyset.
- For n > 0 :
(x_1, x_2, x_3, \ldots, x_n) = ((x_1, x_2, x_3, \ldots, x_{n-1}), x_n).
This definition can be applied recursively as follows :
(x_1, x_2, x_3, \ldots, x_n) = ((\ldots(((\emptyset, x_1), x_2), x_3), \dots), x_n).
For example,
(4, 5, 6) = ((4, 5),6) = (((\emptyset, 4), 5),6)
Cartesian Product
Marie is hungry after a rigorous session of mathematics 😜 and decides to have lunch. She wants to have a main course followed by a dessert. She has 3 options for main course and 3 options for dessert as shown below.


We can view Marie having lunch as a procedure comprising of 2 steps with 3 options for step 1 and after the completion of step 1 there are 3 options for step 2 as shown below.

What are the various possible ways that Marie can have lunch by choosing 1 main course and 1 dessert? We can answer this question by constructing a set of all ordered pairs (x, y) where x is one of the three possible choices for the main course and similarly, y for the dessert. Such a set of all possible ordered pairs where each ordered pair comprises of the first element from the first set and the second element from the second set is called the Cartesian product of two sets.
Also, since there are 3 options for main course and 3 for dessert, the number of ways Marie could have her lunch is 3 \times 3 = 9 ways. So the set of all possible ordered pairs consists of 9 ordered pairs.
This is illustrated below.

Definition
The Cartesian product of two sets X \text{ and } Y, denoted by X \times Y, is the set of all ordered pairs (x, y), where x belongs to X and y belongs to Y.
That is,
X \times Y = \{(x, y) : x \in X \text{ and } y \in Y\}Properties of Cartesian Product
Non-commutativity
For any two sets X \text{ and } Y, the Cartesian product X \times Y is not commutative. That is,
X \times Y \neq Y \times X
because the order of elements in the ordered pair is reversed unless at least one of the following conditions is satisfied, namely, X = Y or X \text{ or } Y is an empty set.
Let us consider the following examples to illustrate the non-commutativity of X \times Y.
Suppose X = \{4, 5\} \text{ and } Y = \{6, 7\}. Then,
\begin{equation*}
\begin{split}
X \times Y &= \{4, 5\} \times \{6, 7\} = \{(4, 6), (4, 7), (5, 6), (5, 7)\} \\
Y \times X &= \{6, 7\} \times \{4, 5\}= \{(6, 4), (6, 5), (7, 4), (7, 5)\} \\
\end{split}
\end{equation*} We can see that X \times Y \neq Y \times X because for all (x, y) \in X \times Y, x \neq y \text{ and consequently, }(x, y) \neq (y, x) .
Now, suppose X = Y = \{4, 5\}. Then,
\begin{equation*}
\begin{split}
X \times Y &= \{4, 5\} \times \{4, 5\} = \{(4, 4), (4, 5), (5, 4), (5, 5)\} \\
Y \times X &= \{4, 5\} \times \{4, 5\} = \{(4, 4), (4, 5), (5, 4), (5, 5)\} \\
\end{split}
\end{equation*} In this case, X \times Y = Y \times X because X = Y.
Finally, suppose X = \{4, 5\} \text{ and } Y = \emptyset. Then,
\begin{equation*}
\begin{split}
X \times Y &= \{4, 5\} \times \emptyset = \emptyset \\
Y \times X &= \emptyset \times \{4, 5\} = \emptyset \\
\end{split}
\end{equation*} In this case, X \times Y = Y \times X = \emptyset.
Non-associativity
The Cartesian product is not associative unless one of the involved sets is empty. That is,
(X \times Y) \times Z \neq X \times (Y \times Z)
where X, Y \text{ and } Z are sets.
For example, suppose X = \{1\}, Y = \{2\} \text{ and } Z = \{3\}. Then,
\begin{equation*}
\begin{split}
(X \times Y) \times Z &= \big(\{1\} \times \{2\}\big) \times \{3\} = \Big(\big\{(1, 2)\big\}\Big) \times \{3\} = \Big\{\big((1, 2), 3\big)\Big\}\\
X \times (Y \times Z) &= \{1\} \times \big(\{2\} \times \{3\}\big) = \{1\} \times \Big(\big\{(2, 3)\big\}\Big) = \Big\{\big(1, (2,3)\big) \Big\} \\
\end{split}
\end{equation*} We can see that (X \times Y) \times Z \neq X \times (Y \times Z).
Cartesian Products of Several Sets
n-ary Cartesian Product
Marie is really really hungry 😧 and would like to have more than 2 courses for lunch. Now her lunch consists of n courses, where n is a positive integer greater than 2, with m_1 options for the first course (course 1) and after the completion of course i-1 \, (\text{where } i = 2, \ldots, n), there are m_i options for course i and so on till the n courses are completed. In this case, all the possible ways she could have her lunch could be represented as a set of ordered n\text{-}tuples called the n\text{-}ary Cartesian product defined over n sets, where each set enumerates the various options available for a particular course and each n\text{-}tuple represents one specific way in which Marie could lunch.
In general, whenever a task can be decomposed into n steps, where n is a positive integer greater than 1, with m_1 options for step 1 and after completion of step i-1 \, (\text{where } i = 2, \ldots, n), there are m_i options for step i and so on till the n steps are completed, then all the possible ways the task could be completed can be enumerated as a set of ordered n\text{-}tuples called the n\text{-}ary Cartesian product defined over n sets, where each set enumerates the various options available to complete a particular step and each n\text{-}tuple is an enumeration of one particular way to perform the task.
Definition
The n\text{-}ary Cartesian product over n non-empty sets X_1, \ldots, X_n is defined as the set
X_1 \times \ldots \times X_n = \big\{(x_1, \ldots, x_n) \,\,|\,\, x_i \in X_i \text{ for every } i \in \{1, \dots, n\}\big\}of n\text{-}tuples.
n-ary Cartesian Power
The Cartesian square of a set X is the Cartesian product X^2 = X \times X.
For example, the 2\text{-}dimensional space (also called a plane) \mathbb{R}^2 = \mathbb{R} \times \mathbb{R} where \mathbb{R} is the set of real numbers is a Cartesian square on the set \mathbb{R}; \mathbb{R}^2 is the set of all points (x, y) on the plane, where x and y are real numbers.
The n\text{-}ary Cartesian power of set X, denoted by X_n, is defined as
X^n = \underbrace{X \times X \times \ldots \times X}_{n} = \big\{(x_1, \ldots, x_n) \,\,|\,\, x_i \in X \text{ for every } i \in \{1, \dots, n\}\big\}For example, the 3\text{-}ary Cartesian power of set \mathbb{R} where \mathbb{R} is the set of real numbers, is the 3\text{-}dimensional space
\mathbb{R}^3 = \mathbb{R} \times \mathbb{R} \times \mathbb{R}; \mathbb{R}^3 is the set of all points (x, y, z) on the 3\text{-}dimensional space, where x, y and z are real numbers.
More generally, \mathbb{R}^n, the n\text{-}ary Cartesian power of set \mathbb{R} where \mathbb{R} is the set of real numbers is the set of all points (x_1, \ldots, x_n) on the n\text{-}dimensional space, where x_i \in \mathbb{R \text{ for every } i \in \{1, \dots, n\}}.
Cardinality of Cartesian Product
Suppose Marie has 3 courses for lunch; there are 4 options to choose from for the first course, 3 options for the second course and 5 options for the third course. We have already seen that all the possible ways she could have her lunch is the Cartesian product defined over the 3 sets, each set representing a course. The number of possible ways she could have her lunch is the number of elements in this Cartesian product over the 3 sets which is equal to the product of the number of elements in each of the 3 sets i.e., 4 \times 3 \times 5 = 60.
More generally, if a procedure can be broken into n steps such that here m_1 options for step 1 and upon completion of step i-1 where i = 2, \ldots, n, there are m_i options for step i and so on till the n\text{th} step is completed, then the number of ways of performing the procedure is m_1 \times m_2 \times \ldots \times m_n.
In set-theoretic terms, if sets X_1, X_2, \ldots, X_n are finite, then
|X_1 \times X_2 \times \ldots \times X_n| = |X_1| \cdot|X_2| \cdot \ldots \cdot |X_n|
where |X_1 \times X_2 \times \ldots \times X_n| denotes the cardinality of the n\text{-}ary Cartesian product defined over n sets; the cardinality of a set is equal to the number of elements in the set.
That is, the cardinality of the n\text{-}ary Cartesian product defined over n sets is equal to the product of the cardinalities of the n sets over which it is defined.
Binary Relation
Suppose we have a set of four actors, A = \{\text{Tom Cruise, George Clooney, Timothée Chalamet, Anne Hathaway}\} and a set of three movies, M = \{\text{Mission Impossible, Midnight in Paris, Dune}\}.
A possible relation on A \text{ and } M is the relation “acted in”, given by
R = \{(\text{Tom Cruise, Mission Impossible}), (\text{Timothée Chalamet, Dune}) \}That is, Tom Cruise acted in Mission Impossible and Timothée Chalamet acted in Dune. George Clooney and Anne Hathaway did not act in any of the movies in the set M and the movie Midnight in Paris did not feature any of the actors in set A.
We can see that the set R associates elements of set A with the elements of set M.
The set R could therefore be viewed as a subset of the Cartesian product of the two sets A \text{ and }M denoted by A \times M, which is the set of all ordered pairs (a, m) where a belongs to set A and m belongs to set M. That is,
A \times M = \{(a, m) \,|\, a \in A \text{ and } b \in B\}Therefore,
\begin{equation*}
\begin{split}
A \times M &= \{(\text{Tom Cruise, Mission Impossible}), (\text{Tom Cruise, Midnight In Paris}), (\text{Tom Cruise, Dune}), \\
&\quad\quad(\text{George Clooney, Mission Impossible}), (\text{George Clooney, Midnight In Paris}), (\text{George Clooney, Dune}), \\
&\quad\quad(\text{Timothée Chalamet, Mission Impossible}), (\text{Timothée Chalamet, Midnight In Paris}), (\text{Timothée Chalamet, Dune}), \\
&\quad\quad(\text{Anne Hathaway, Mission Impossible}), (\text{Anne Hathaway, Midnight In Paris}), (\text{Anne Hathaway, Dune}) \}
\end{split}
\end{equation*} We can see that R \subseteq A \times M.
A binary relation associates elements of one set, called the domain, with elements of another set, called the codomain.
A binary relation over sets X \text{and } Y is a new set of ordered pairs (x, y) consisting of elements x from X and y from Y. That is, an element x is related to an element y if and only if the pair (x, y) belongs to the set of ordered pairs that defines the binary relation.
It should be noted that the binary relation R over sets X and Y can be defined solely as a set of ordered pairs (x, y) where x \in X and y \in Y, without specifying the underlying relationship between x and y. That is, a binary relation R over sets X \text{ and } Y does not require a specific reason to relate or associate x \in X to y \in Y.
In the example above, the following is another binary relation R over sets A \text{ and } M.
R = \{(\text{George Clooney, Midnight In Paris}), (\text{Anne Hathaway, Dune}), (\text{Tom Cruise, Mission Impossible})\}R \subseteq A \times M but does not specify the relationship between the actor and the movie in each of its ordered pair i.e., the binary relation R over sets A \text{ and } M does not specify why a \in A relates to m \in M.
Definition
A binary relation R over sets X \text{and } Y is a subset of the Cartesian product X \times Y i.e., R \subseteq X \times Y.
The set X is called the domain of R and the set Y is called the codomain of R.
The statement (x, y) \in R reads “x is R-related to y” and is denoted by xRy.
When X = Y, a binary relation is called a homogeneous relation or endorelation.
In a binary relation, the order of elements is important i.e., if x \neq y then yRx can be true or false independently of xRy. For example, 2 divides 8 but 8 does not divide 2.
Types of Binary Relations
The following are some important types of binary relations over sets X \text{ and } Y.
Function
A function, denoted by f, is a special type of binary relation over sets X \text{ and } Y that satisfies the following conditions:
- For every x \in X there exists y \in Y such that (x, y) \in f
- (x, y) \in f \text{ and } (x, z) \in f imply that y = z
A function is also called a map or mapping.
Since f is a binary relation over sets X \text{ and } Y \!\!\text{,} it follows that it is a subset of their Cartesian product, X \times Y i.e., f \subseteq X \times Y. This relationship is usually written as f : X \rightarrow Y and read as “f is a function from X \text{ to } Y \text{"} or “f maps X \text{ to } Y \text{"}. The set X is called the domain of f and the set Y is called the codomain of f.
When (x, y) \in f, we write y = f(x). We say that y is the image of f at x (or value of f \text{ at } x) and that x is a pre-image of y.
Homogeneous Relation
A homogeneous relation over a set X is a binary relation over X and itself i.e., it is a subset of the Cartesian product X \times X. This is commonly phrased as “a relation on X” or “a binary relation over X\text{"}.
Some important properties that a homogeneous relation R over a set X may have are :
Reflexive
A binary relation R on a set X is reflexive if it relates every element of X to itself i.e., for all x \in X, xRx, where the notation xRx means that (x, x) \in R.
For example, “is equal to” is a reflexive relation on the set of real numbers since every real number is equal to itself.
Irreflexive
A binary relation R on a set X is irreflexive if it does not relate any element of X to itself i.e., if xRx holds for no x \in X. This means that for all x \in X, (x, x) \not \in R.
For example, “is greater than” is an irreflexive relation on the set of real numbers since there is no real number which is greater than itself.
A relation is irreflexive if and only if its complement in X \times X is reflexive.
For example, “is less than or equal to” is a reflexive relation on the set of real numbers, while its complement “is greater than” is an irreflexive relation.
It should also be noted that not every relation which is not reflexive is irreflexive i.e., it is possible to define relations where some elements are related to themselves but others are not.
For example, the binary relation “the product of x \text{ and }y is even” is reflexive on the set of even numbers, irreflexive on the set of odd numbers and neither reflexive nor irreflexive on the set of integers.
Symmetric
A binary relation R on a set X is symmetric if for all x, y \in X, \text{ if } xRy \text{ then } yRx.
That is, if (x, y) \in R \text{ then } (y, x) \in R \text{ for all } x, y \in X.
For example, “is parallel to” is a symmetric relation on the set of all lines in the Euclidean plane because for any two lines \overleftrightarrow{AB} \text{ and } \overleftrightarrow{CD}, if \overleftrightarrow{AB} \parallel \overleftrightarrow{CD} is true, then \overleftrightarrow{CD} \parallel \overleftrightarrow{AB} is also true.
Antisymmetric
A binary relation R on a set X is antisymmetric if there is no pair of distinct elements of X each of which is related by R to the other.
That is, R is antisymmetric if for all x, y \in X,
if xRy with x \neq y then yRx must not hold,
or equivalently,
if xRy \text{ and } yRx \text{ then } x = y.
The divisibility relation on the set of positive integers is antisymmetric. If m \text{ and } n are two positive integers which are distinct, then if m divides n, then n cannot divide m. For example, 9 is divisible by 3 but 3 is not divisible by 9.
The definition of antisymmetry says nothing about whether xRx holds or not for any x \in X.
An antisymmetric relation R on a set X may be reflexive (i.e., xRx \text{ for all } x \in X), irreflexive (i.e., xRx \text{ for no } x \in X) or neither reflexive or irreflexive.
For example, the order relation “is greater than or equal to” on the set of real numbers is reflexive and antisymmetric. Any real number a is greater than or equal to itself i.e., a \geq a \text{ for all } a \in \mathbb{R}. Hence “is greater than or equal to” is reflexive. But for any two distinct real numbers a, b \in \mathbb{R}, if a \geq b then b \geq a cannot hold when a \neq b. So the relation is antisymmetric.
Similarly, the order relation “is greater than” on the set of real numbers is irreflexive and antisymmetric. No real number a is greater than itself i.e., a > a \text{ for no } a \in \mathbb{R}. So the relation “is greater than” on the set of real numbers is irreflexive. However, for any two distinct real numbers a, b \in \mathbb{R}, if a > b then b > a cannot hold when a \neq b. So the relation is antisymmetric.
Asymmetric
A binary relation R on a set X is asymmetric where for all x, y \in X, if x is related to y then y is not related to x.
The following is a more formal definition of an asymmetric relation.
The binary relation R on a set X is asymmetric if for all x, y \in X, if xRy is true then yRx is false, i.e., if (x, y) \in R then (y, x) \not \in R.
The following two definitions are logically equivalent to the above definition.
The binary relation R on a set X is asymmetric if for all x, y \in X, at least one of xRy \text{ and } yRx is false.
Equivalently,
The binary relation R on a set X is asymmetric if for all x, y \in X, at most one of xRy \text{ and } yRx is true.
Therefore, a relation is asymmetric if and only if it is both antisymmetric and irreflexive.
An example of an asymmetric relation is the relation “is greater than” on the set of real numbers. For any two real numbers a \text{ and } b, if a > b then necessarily b is not greater than a.
The relation “is greater than or equal to” on the set of real numbers is not asymmetric because when two real numbers are the same i.e., when a = b, reversing a \geq a produces a \geq a and both are true.
An asymmetric relation is not the same as a “not symmetric” relation. The “is greater than or equal to” on the set of real numbers is an example of a relation that is neither symmetric nor asymmetric.
Transitive
A binary relation R on a set X is transitive if, for all elements x, y, z \in X, whenever R relates x to y and y to z, then R also relates x to z.
The following is a formal definition of a transitive relation.
A homogeneous relation R on a set X is a transitive relation if, for all x, y, z \in X, if xRy and yRz then xRz. That is, if (x, y) \in R \text{ and } (y, z) \in R then it must be the case that (x, z) \in R.
The relations “is greater than” on a set of real numbers and “is congruent to” on the set of all line segments in the Euclidean plane are two examples of transitive relations.
For example, for any three real numbers, a, b, c \in \mathbb{R}, whenever a > b \text{ and } b > c, then a > c.
Since 5 > 4 \text{ and } 4 > 2, it follows that 5 > 2.
Similarly, for any three line segments, say \overline{AB}, \overline{CD} \text{ and } \overline{EF}, if \overline{AB} \cong \overline{CD} \text{ and } \overline{CD} \cong \overline{EF} then \overline{AB} \cong \overline{EF}.
The homogeneous relation “is perpendicular to” on the set of all lines in the Euclidean plane is an example of a non-transitive relation. As shown below, \overleftrightarrow{AB} \perp \overleftrightarrow{CD} \text{ and } \overleftrightarrow{CD} \perp \overleftrightarrow{EF} \text{ but } \overleftrightarrow{AB} \not \perp \overleftrightarrow{EF}, in fact \overleftrightarrow{AB} \parallel \overleftrightarrow{EF}.

Connected
A binary relation R on a set X is called connected when for all x, y \in X, if x \neq y then xRy \text{ or } yRx.
That is, a relation R on a set X is called connected when for all x, y \in X, xRy \text{ or } yRx \text{ or } x = y.
The relation “is greater than” on the set of real numbers is an example of a connected relation. For any two distinct real numbers, a \text{ and } b, either a > b or b > a.
Strongly Connected
A binary relation R on a set X is called strongly connected when for all x, y \in X, xRy \text{ or } yRx.
For example, “is greater than or equal to” on the set of real numbers is a strongly connected relation. For any two real numbers, a \text{ and } b when a \neq b, either a \geq b or b \geq a and when a = b, a \geq b and b \geq a become a \geq a and a \geq a, both of which hold.
Dense
A binary relation R on a set X is called dense when for all x, y \in X, if xRy then there exists some z \in X such that xRz \text{ and } zRy.
The relation “is greater than” on the set of real numbers is an example of a dense relation. For example, for any two real numbers a \text{ and } b if a > b, then we can always find a real number c such that a > c > b. We can see that for the real numbers 4 \text{ and } 5, 5 > 4 and there is a real number 4.5 such that 5 > 4.5 > 5.
However, “is greater than” on a set of integers is not a dense relation. For integers, 4 \text{ and } 5, 5 > 4 but since there is no integer between 4 \text{ and } 5, consequently, there is no integer that is lesser than 5 and greater than 4.
Equivalence Relation
Intuition
Lets do a party trick. Suppose you want to nerd out on a party of poets by flaunting your math superpower 🚀💪. You nonchalantly ask the poets to find the last two digits of 99^{3007}. If there is a poet with a good mathematical acumen, how would he go about finding the answer to this question? It would be obvious to him that finding the answer by multiplying 99 with itself 3007 times is out of question. So he would think of ways to reduce this problem into an equivalent problem that is much easier to solve.
The simplest way to find the last two digits of any positive integer is to divide the number by 100 and take its remainder. For example to find the last two digits of number 127, divide 127 by 100. This would result in 27 and hence 2 \text{ and } 7 are the last two digits of the number 127. In order to find the last two digits of 99^{3007} we will divide this number by 100 and find its remainder. But now we have a problem. It is not easy to calculate which number equals 99^{3007}. So how do we solve this? We need to find another number, say x, equivalent to 99 such that when x^{3007} is divided by 100, it leaves the same remainder as when 99^{3007} is divided by 100 and also x^{3007} is much easier to calculate than 99^{3007}. We say that x is equivalent to 99 in the context of division by 100 if it leaves the same reminder as 99 when divided by 100, where the reminder is an integer between 0 \text{ and } 99. This is because in any calculation that involves finding the remainder when 99 is divided by 100, 99 can be replaced by its equivalent number x to yield the same result.
Let us now find such a number x. We can see that,
-1 = (-1) \times 100 + 99
Therefore, we can see that when -1 is divided by 100 it leaves the same remainder 99 as when 99 is divided by 100. Let us replace 99 by -1 and see whether we can solve the problem.
(-1)^{3007} = -1Since -1 leaves a remainder of 99 when divided by 100 and -1 is equivalent to 99 in the context of division by 100 the last two digits of 99^{3007} when divided by 100 are 9 \text{ and } 9.
We can see that this concept of equivalence is useful in simplifying calculations which otherwise wouldn’t have been possible.
We can also see that there are numbers other than -1 that leave the same remainder 99 when divided by 100. These numbers form an equivalence class i.e., they partition the underlying set namely the set of integers into a subset such that every element of the subset is equivalent to every other element of the subset with respect to the equivalence relation. For example, the numbers that leave the remainder of 99 when divided by 100 form an equivalence class which is an infinite set of integers as shown below.
\{\ldots,-201, -101, -1, 99, 199, 299, \ldots\}In calculations involving remainders upon division by 100, any number in this set can be replaced by any other number in the set without altering the result of the calculation.
Since when a number is divided by 100, it could result in 100 remainders ranging from integers 0 \text{ to } 99, there is an equivalence class associated with each of these remainders. Each of these equivalence classes form an infinite set of integers and each set is disjoint from the other sets because any integer belongs to only one equivalence class since upon division by 100 it leaves an unique remainder.
For example,
\{\ldots,-200, -100, 0, 100, 100, 300, \ldots\}is an infinite set of integers such that every integer in the set leaves a remainder 0 when divided by 100. We can see that this set has no elements in common with the set that leaves a remainder of 1 when divided by 100 and hence is disjoint from it.
Now that we have understood the relevance of an equivalence relation on a set, let us proceed to define it.
The equivalence relation on a set is a generalization of the notion of equality between any two elements of the set. It specifies a rule or a test to check whether two elements in a set are the same.
Definition
A homogeneous relation R on a set X is said to be an equivalence relation, if and only if it is reflexive, symmetric and transitive. That is, for all x, y \text{ and } z \text{ in } X :
- xRx (reflexivity)
- xRy if and only if yRx (symmetry)
- If xRy \text{ and } yRz then xRz (transitivity)
X together with the relation R is called a setoid. That is, a setoid is a set X equipped with an equivalence relation R.
Notation
The various notations used in literature to denote the equivalence relation R between two elements x \in X \text{ and } y \in X are \text{``}x \sim y \text{"} \text{ or } \text{``}x \equiv y\text{"} when R is implicit and variations of \text{``}x \sim_R y \text{"} , \text{``} x \equiv_R y \text{"} \text{ or } \text{``}xRy\text{"} are used to specify R explicitly.
Non-equivalence may be written as either \text{``}x \not \sim y\text{"} \text{ or } \text{``}x \not \equiv y\text{"}.
Examples of Equivalence Relations
Equality Relation
The “is equal to” relation on any given set S, denoted by =, is an example of an equivalence relation.
We will formalize this observation as a theorem and subsequently prove it.
Theorem
For any given set S, if R is a relation induced by equality on S, then R is an equivalence relation on S.
Proof.
Let S be a set with a relation R induced by equality. That is, \forall x, y \in S \, (xRy \Leftrightarrow x = y). Then S satisfies the following properties:
- Reflexivity: \forall x \in S \, (xRx) (by the Reflexivity of Equality)
- Symmetry: \forall x, y \in S \, (xRy \implies yRx) (by the Symmetry of Equality)
- Transitivity: \forall x, y, z \in S \, \big[(xRy \land yRz) \implies xRz\big] (by the Transitivity of Equality)
By definition, if R is an equivalence relation on S, then R must satisfy the following conditions:
- Reflexivity: \forall x \in S, x R x
- Symmetry: \forall x, y \in S, (x R y \implies y R x)
- Transitivity: \forall x, y, z \in S, (x R y \land y R z \implies x R z)
Since we have shown above that the relation R induced by equality on the set S satisfies the properties of reflexivity, symmetry and transitivity, by definition, R is an equivalence relation on the set S.
Therefore, we have shown that if R is a relation induced by equality on any set S, then R is an equivalence relation on S.
Using logic symbols, we can express the theorem as follows:
\forall S\, \bigg( \Big(R = {(x,y) \mid x,y \in S \land x = y}\Big) \implies \Big( \forall x \in S\, (x R x) \land \forall x, y \in S\, (x R y \implies y R x) \land \forall x, y, z \in S\, \big((x R y) \land (y R z) \implies (x R z)\big) \Big) \bigg)Congruence modulo n Relation
For every integer n greater than 1, the congruence modulo n, is an equivalence relation on the set of integers \mathbb{Z}, for which two integers x \in \mathbb{Z} \text{ and } y \in \mathbb{Z} are equivalent or in this case called congruent, written
x \equiv y \pmod n
if n divides x-y or equivalently, if x \text{ and } y have the same remainder when divided by n.
For example,
27 \equiv 12 \pmod{5}Both 27 \text{ and } 12 have the same remainder 2 when divided by 5. Equivalently, 27-12 = 15 is divisible by 5. Hence, 27 \text{ and } 12 are congruent modulo 5.
It should be noted that we excluded the case n = 1 due to its triviality because any two integers is congruent modulo \mathit{1} since every integer has 0 as remainder when divided by 1.
The “congruence modulo n” relation R on the set of integers \mathbb{Z} is defined as :
R = \big\{(x, y) \,|\, x \in \mathbb{Z}, y \in \mathbb{Z}, x \equiv y \!\!\!\pmod{n}\big\}To prove that congruence modulo n is an equivalence relation on the set of integers, we have to show that R is reflexive, symmetric and transitive.
R is reflexive because every integer is congruent to itself. That is, x \equiv x \pmod{n} \text{ for all } x \in \mathbb{Z} because x - x = 0 is divisible by any n .
R is symmetric because for any two integers x \text{ and } y if x \equiv y \pmod{n} \text{ then } y \equiv x \pmod{n}.
If x \equiv y \pmod{n} then x - y = kn, where k is an integer. Consequently, y - x = (-k)n, where -k is also an integer. Therefore, we have y \equiv x \pmod{n}.
R is transitive because for any three integers x, y \text{ and } z if x \equiv y \pmod{n} \text{ and } y \equiv z \pmod{n}\text{ then } x \equiv z \pmod{n}.
If x \equiv y \pmod{n} \text{ and } y \equiv z \pmod{n}\text{ then },
\begin{equation*}
\begin{split}
x - y &= kn \text{ and } \\
y - z &= ln \\
\end{split}
\end{equation*} where k \text{ and } l are some integers.
Adding the two equations,
(x -y) + (y-z) = kn + ln
Hence,
x - z = (k+l)n
Since k \text{ and } l are integers, k+l is also an integer. Therefore, x \equiv z \pmod{n} which proves that R is transitive.
Hence we have proved that congruence modulo n is an equivalence relation on the set of integers, \mathbb{Z}.
Similarity Relation
The “is similar to” relation on the set of all triangles, denoted by \sim, is another example of an equivalence relation.
The “is similar to” relation R on the set of all triangles T is defined as :
R = \Big\{\big(\triangle ABC, \triangle DEF\big) \,|\, \triangle ABC \in T, \triangle DEF \in T, \triangle ABC \sim \triangle DEF\Big\}We prove that R is an equivalence relation on the set of all triangles by showing that R is reflexive, symmetric and transitive.
One way to show that two triangles are similar is using SSS similarity which states that two triangles are similar if and only if each side of one triangle is the same constant multiple of the corresponding side of the other triangle.
That is, for any two triangles \triangle ABC \text{ and } \triangle DEF,
\triangle ABC \sim \triangle DEF \,\,\text{ if and only if }\,\, \frac{AB}{DE} = \frac{BC}{EF} = \frac{CA}{FD}R is reflexive because any triangle \triangle ABC is similar to itself. That is, \triangle ABC \sim \triangle ABC \text{ for all } \triangle ABC \in T. This is because,
\frac{AB}{AB} = \frac{BC}{BC} = \frac{CA}{CA} = 1R is symmetric because for any two triangles \triangle ABC \text{ and } \triangle DEF if \triangle ABC \sim \triangle DEF \text{ then } \triangle DEF \sim \triangle ABC.
If \triangle ABC \sim \triangle DEF then,
\frac{AB}{DE} = \frac{BC}{EF} = \frac{CA}{FD}Taking the reciprocal of each fraction doesn’t change the equality, i.e., since \dfrac{AB}{DE} = \dfrac{BC}{EF} = \dfrac{CA}{FD} it also implies that,
\frac{DE}{AB} = \frac{EF}{BC} = \frac{FD}{CA}The above equality implies that \triangle DEF \sim \triangle ABC. Hence, R, the “is similar to” relation on the set of all triangles is symmetric.
R is transitive because for any three triangles \triangle ABC, \triangle DEF \text{ and } \triangle GHI if \triangle ABC \sim \triangle DEF \text{ and } \triangle DEF \sim \triangle GHI \text{ then } \triangle ABC \sim \triangle GHI.
If \triangle ABC \sim \triangle DEF then,
\frac{AB}{DE} = \frac{BC}{EF} = \frac{CA}{FD}Similarly, if \triangle DEF \sim \triangle GHI then,
\frac{DE}{GH} = \frac{EF}{HI} = \frac{FD}{IG}Multiplying the first equation by a constant say \dfrac{DE}{GH} does not change equality. That is,
\frac{AB}{DE} \times \frac{DE}{GH} = \frac{BC}{EF} \times \frac{DE}{GH} = \frac{CA}{FD} \times \frac{DE}{GH}Since \dfrac{DE}{GH} = \dfrac{EF}{HI} = \dfrac{FD}{IG},
\frac{AB}{DE} \times \frac{DE}{GH} = \frac{BC}{EF} \times \frac{EF}{HI} = \frac{CA}{FD} \times \frac{FD}{IG}Therefore,
\frac{AB}{GH} = \frac{BC}{HI} = \frac{CA}{IG}Hence,
\triangle ABC \sim \triangle GHI
Thus we have proved that the similarity relation is an equivalence relation on the set of triangles.
Equivalence Class
We have already discussed that two integers are equivalent with respect to division by 100 if they produce the same remainder upon division by 100 because then one integer can be replaced by the other in a calculation involving division by 100 without altering the result. These two integers belong to a subset of the set of integers, called the equivalence class, such that any element of this subset has the same nonnegative integer as remainder when divided by 100. Consequently, any element belonging to an equivalence class can be replaced with any other element from the same equivalence class in a calculation involving division by 100 without changing the result. Since an integer upon division by 100 can result in any one of the 100 possible nonnegative numbers between 0 \text{ to } 99 as remainders, there are 100 equivalence classes each corresponding to a subset of integers that produces one of the 100 possible remainders upon division by 100.
The equivalence class modulo n of an integer x \in \mathbb{Z} is the set of all integers such that each integer in the set produces the same remainder as x does upon division by n. That is, it is the set of all integers of the form x + kn, where k is any integer since x + kn \equiv x \pmod{n}. It is called the congruence class or residue class of x modulo n and is denoted as (x mod n), or as \bar{x} or [x] when the modulus n is known from the context.
The congruence modulo n equivalence relation on the set of integers \mathbb{Z} such that x \sim y if and only if they produce the same non-negative integer as remainder when divided by n gives rise to exactly n equivalence classes, one class for each of the n possible remainders between 0 \text{ to } n-1 that result when an integer is divided by n. This set of n equivalence classes of integers with respect to the congruence modulo n equivalence relation on the set of integers \mathbb{Z} is denoted by \mathbb{Z}/n\mathbb{Z}.
For n > 1,
\mathbb{Z}/n\mathbb{Z} = \big\{[x]_n : x \in \mathbb{Z}\big\} = \big\{[0]_n, [1]_n, [2]_n, \ldots, [n-1]_n\big\}As we have just seen, when the elements of some set S have a notion of equivalence formalized as an equivalence relation, then we may naturally split the set S into equivalence classes. These equivalence classes are constructed such that elements a \text{ and } b belong to the same equivalence class if and only if they are equivalent.
Definition
Given a set X and an equivalence relation \sim on X, the equivalence class of an element x \in X is denoted by [x] \text{ or } [x]_{\sim} and is defined as,
[x] = \{y \in X : x \sim y\}Quotient Set
The set of all equivalence classes of X with respect to an equivalence relation \sim, denoted by X\!/\!\!\sim and defined as X\!/\!\!\sim \, := \{[x] : x \in X\}, is called the quotient set of X with respect to an equivalence relation \sim.
Projection
Given a set X and an equivalence relation \sim on X, the projection of \sim is the function \pi : X \rightarrow X\!/\!\!\sim defined by \pi(x) = [x] which maps elements of X into their respective equivalence classes by \sim on X.
Properties of Equivalence Classes
Given a set X and an equivalence relation \sim on X, the following properties hold good.
Every element x of X is a member of the equivalence class [x]. That is,
\forall x \in X, x \in [x]
For any two elements x, y \in X, x \sim y if and only if [x] = [y].
First we will prove that if x \sim y then [x] = [y].
Suppose x \sim y.
Let z \in [x]. Then by definition of equivalence class, z \sim x.
By symmetric property of equivalence relation, y \sim x \text{ and } x \sim z.
Hence, by transitive property of equivalence relation, y \sim z. Therefore, z \in [y].
We have show that any element z \text{ of } [x] is also an element of [y].
By reversing the roles of x \text{ and } y in the argument above we can conclude that any element of [y] is also an element of [x]. Therefore, [x] = [y].
Let us now prove that if [x] = [y] then x \sim y.
Suppose [x] = [y].
By reflexive property of equivalence relation, x \sim x. Therefore, x \in [x].
By our hypothesis, since [x] = [y], it implies that x \in [y]. Hence, by definition of equivalence class, x \sim y.
Every two equivalence classes [x] and [y] are either equal or disjoint.
For any two arbitrary sets and consequently, for two equivalence classes [x] and [y] arising from the equivalence relation \sim on X, there are in general three possibilities :
- [x] \cap [y] \neq \empty \text{ and } [x] = [y]
- [x] \cap [y] \neq \empty \text{ and } [x] \neq [y]
- [x] \cap [y] = \empty
If [x] \cap [y] = \empty , then the equivalence classes [x] \text{ and } [y] are disjoint and there is nothing to prove.
On the contrary, if [x] \cap [y] \neq \empty , then there is an element z \in X such that z \in [x] \text{ and } z \in [y]. Therefore, from the definition of equivalence class, z \sim x \text{ and } z \sim y.
By the symmetry property of equivalence relation if z \sim x \text{ then } x \sim z. So we have, x \sim z \text{ and } z \sim y. By transitive property of equivalence relation this implies that x \sim y. From the definition of equivalence class, this implies that [x] = [y].
Hence we have proved that any two equivalence classes that rise from an equivalence relation on a set are either equal or disjoint.
Consequently, every element x of X belongs to one and only one equivalence class.
It follows from the properties discussed above that if \sim is an equivalence relation on a set X and x \text{ and } y are two elements of X, the following statements are equivalent :
- x \sim y
- [x] = [y]
- [x] \cap [y] \neq \empty
Partition of Sets and Equivalence Classes
Consider a set of fruits as shown below. This set consists of 6 apples, 5 mangoes, 4 oranges and 3 bunches of grapes.
Suppose we split this set of fruits into subsets based on the type of fruits as shown below. We can see that each subset is non-empty and every element of the set of fruits belongs to only one subset and consequently, the subsets are disjoint. Such a “partition” of the set of fruits based on the type of fruit can also be viewed as a set with an equivalence relation, namely, two fruits are equivalent if they are of the same type and each subset corresponds to an equivalence class.
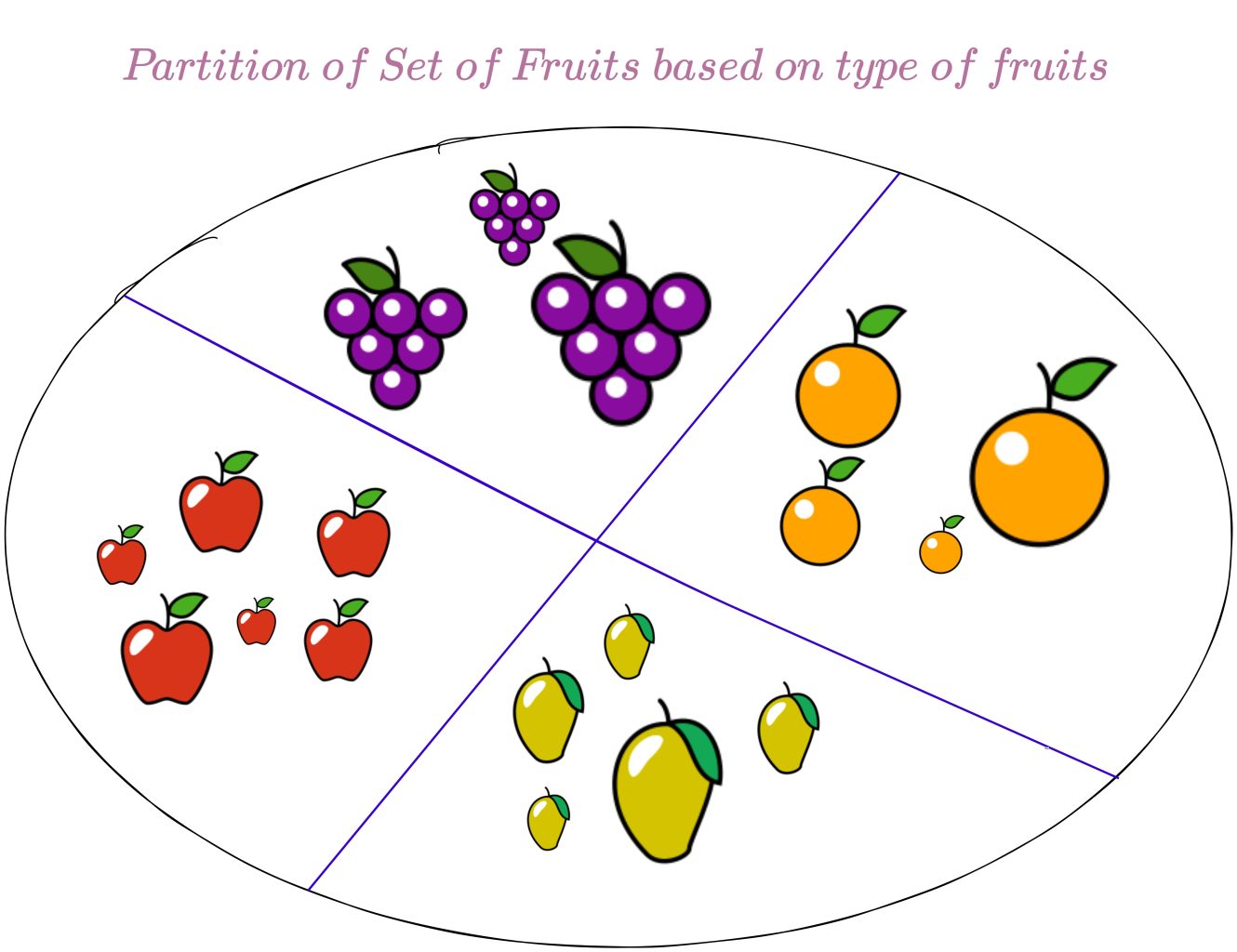
We have illustrated through this example that a partition of a set is a grouping of its elements into non-empty subsets, in such a way that each element is included in exactly one subset.
Every equivalence relation on a set defines a partition of this set and every partition defines an equivalence relation. A set equipped with an equivalence relation or a partition is also called a setoid.
Definition
A partition of a set X is a set of non-empty subsets of X such that every element x in X is in exactly one of these subsets i.e., the subsets are non-empty mutually disjoint sets.
Equivalently, a family (or collection) of sets P is a partition of X if and only if all of the following conditions hold.
- The family P does not contain the empty set i.e., \empty \not \in P.
- The union of the sets in P is equal to X i.e., \bigcup_{A \in P} = X. The sets in P are said to exhaust or cover X.
- The intersection of any two distinct sets in P is empty i.e., (\forall A, B \in P) \, A \neq B \implies A \cap B = \empty. The elements of P are said to be pairwise disjoint or mutually exclusive.
The sets in P are called the blocks, parts or cells of the partition. If x \in X then we represent the cell containing x by [x] i.e., the cell in P which contains x is denoted by [x].
Fundamental Theorem of Equivalence Relations
For any equivalence relation on a set X, the set of its equivalence classes is a partition of X.
Conversely, from any partition P of X, we can define an equivalence relation on X by setting x \sim y precisely when x \text{ and } y are in the same cell in P.
Thus, the notions of equivalence relation and partition are essentially equivalent.
Examples
The following are some examples of a partition P of a set.
- The empty set \empty has exactly one partition, namely, \empty i.e., if X = \empty, then P = \empty.
- For any non-empty set X, P = \{X\} is a partition of X, called the trivial partition. Every singleton set has exactly one partition. For example, the singleton set X = \{x\} has exactly one partition, namely, P = \{X\} = \{\{x\}\}.
- For any non-empty proper subset X of a set U, the set X together with its complement form a partition of U, namely, partition P = \{X, U \!\setminus\! X\}.
- The set X = \{1, 2, 3\} has 5 possible partitions.
(i) P = \{\{1\}, \{2\}, \{3\}\}
(ii) P = \{\{1\}, \{2, 3\}\}
(iii) P = \{\{1, 3\}, \{2\}\}
(iv) P = \{\{1, 2\}, \{3\}\}
(v) P = \{\{1, 2, 3\}\}
The following are not partitions of the set X = \{1, 2, 3\} :
- \{\{\}, \{1, 2\}, \{3\}\} is not a partition of any set because one of its elements is the empty set.
- \{\{1, 2\}, \{2, 3\}\} is not a partition of any set because the element 2 is contained in more than one cell.
- \{\{1\}, \{2\}\} is not a partition of the set X because none of its cells contains 3.
Representative of an Equivalence Class
Every element of an equivalence class characterizes the class, and may be used to represent it. When such an element is chosen, it is called the representative of the class.
Sometimes, a particular element of an equivalence class is more naturally suited to represent the class as compared to all other elements of the class. Such a representative is called a canonical representative i.e., it denotes the standard way to represent the equivalence class.
Definition of Canonical Form
Given a set S of mathematical objects with an equivalence relation R on S, a canonical form is given by designating some mathematical objects of S to be in “canonical form”, such that every mathematical object under consideration is equivalent to exactly one mathematical object in canonical form.
Therefore, the canonical forms in S represent the equivalence classes once and only once. To test whether two mathematical objects are equivalent, it then suffices to test equality on their canonical forms.
Canonical forms are generally used to make operating with equivalence classes more effective. For example, in the case of the congruence modulo n equivalence relation on the set of integers \mathbb{Z}, each congruence class modulo n may be represented by any one of its members, although we usually represent each congruence class by the smallest nonnegative integer which belongs to that class since this is the remainder which results from division by n. Operations on classes are carried out by combining these representatives and then reducing the result to its remainder when it is divided by n.
Examples of Equivalence Classes
Let X be the set of all triangles and \sim, the equivalence relation “has the same area as”. Then, for every positive real number A, there will be an equivalence class of all triangles that have the area A.
We have already shown that congruence modulo n is an equivalence relation on the set of integers.
The congruence modulo \mathit{4} equivalence relation, R, on the set of integers \mathbb{Z} is defined as :
R = \big\{(x, y) \,|\, x \in \mathbb{Z}, y \in \mathbb{Z}, x \equiv y \!\!\! \pmod{4} \big\}That is, x is equivalent to y if and only if they leave the same non-negative integer as remainder when divided by 4. This equivalence relation gives rise to exactly 4 equivalence classes, one class for each possible remainder when an integer is divided by 4.
The 4 equivalence classes corresponding to the remainders 0, 1, 2 \text{ and } 3 are shown below :
\begin{equation*}
\begin{split}
[0] &= \{\dots, -12, -8, -4, 0, 4, 8, 12, \dots\}\\
[1] &= \{\dots, -11, -7, -3, 1, 5, 9, 13, \dots\}\\
[2] &= \{\dots, -10, -6, -2, 2, 6, 10, 14, \dots\}\\
[3] &= \{\dots, -9, -5, -1, 3, 7, 11, 15, \dots\}\\
\end{split}
\end{equation*} [0], [1], [2] \text{ and } [3] are the canonical representatives of the equivalence classes corresponding to remainders 0, 1, 2 \text{ and }3.
The quotient set, i.e., the set of all equivalence classes of \mathbb{Z} with respect to the congruence modulo n equivalence relation, R, is denoted by \mathbb{Z}\, / 4\mathbb{Z} and is defined as
\mathbb{Z}\, / 4\mathbb{Z} = \{[0], [1], [2], [3]\}Well-definedness under an Equivalence Relation
Suppose \sim is an equivalence relation on set X. Given an element x \in X, the equivalence class of x is the set
[x] = \{y \in X : x \sim y\}The element x is called the representative of the equivalence class [x] and any element of an equivalence class can serve as its representative.
The set of all equivalence classes of X with respect to the equivalence relation \sim is denoted by X\!/\!\!\sim and defined as
X\!/\!\!\sim \, := \{[x] : x \in X\}This set, X\!/\!\!\sim, is called the quotient set of X with respect to \sim.
Since an equivalence class can have different representations, any function we define with X\!/\!\!\sim as its domain should map different representations of the same equivalence class to the same element in its codomain to be considered a well-defined function (or just a function).
Let us illustrate this constraint on the definition of a function with a X\!/\!\!\sim as its domain through an example.
Let us attempt to define a function, f : \mathbb{Z}/7\mathbb{Z} \rightarrow \mathbb{Z}, as f([x]) = x.
We can see that
f([0]) = 0, \,f([2]) = 2, \,f([7]) = 7
and so on. But this definition poses a problem. Since 0 \equiv 7 \pmod{7}, it implies that [0] = [7]. That is, [0] \text{ and } [7] are the exact same element of the set \mathbb{Z}/7\mathbb{Z}. However, as per the “function” we have defined above, f([0]) \neq f([7]). This is a violation of the definition of a function. Hence, f is not a function i.e., f is not well-defined because it maps different representations of the same equivalence class to different elements in its codomain.
Let us attempt to rectify this issue by defining another function with domain \mathbb{Z}/7\mathbb{Z}.
Consider a function, f : \mathbb{Z}/7\mathbb{Z} \rightarrow \{0, 1, 2, 3, 4, 5, 6\}, defined as
f([x]) = x \bmod 7
where x \bmod 7 is the remainder, as in the Division Algorithm, when x is divided by 7. That is, x \bmod 7 denotes the unique integer r such that 0 \leq r < 7 and r \equiv x \pmod 7.
Now,
f([0]) = 0, \,f([2]) = 2, \,f([7]) = 0
We have already shown that [0] = [7] and we can see that f([0]) = f([7]).
If f([x]) is a well-defined function, then for any x \in \mathbb{Z}, f([x]) = f([x^\prime]) whenever x \equiv x^\prime \pmod{7}, i.e., the definition of f([x]) does not depend on the choice of the representative x of the equivalence class.
Let us verify whether f is a well-defined function i.e., whether f([x]) = f([x^\prime]) whenever x \equiv x^\prime \pmod{7}.
Let us assume that there exist some integers x, x^\prime \in X such that x \equiv x^\prime \pmod{7}.
By definition of congruence modulo n, n \,|\, (x - x^\prime) i.e., there exists some integer k \in \mathbb{Z} such that,
x - x^\prime = kn
Substituting n = 7 in the above equation,
x = x^\prime + 7k
Applying the Division Algorithm to x^\prime \text{ and } 7, yields unique integers q \text{ and } r such that,
x^\prime = 7q + r
where r \in \{0, 1, 2, 3, 4, 5, 6\}.
Hence, f([x^\prime]) = r by definition of f.
Combining the above two equations, we get
x = 7q + r + 7k = 7(q+k) + r
Therefore, f([x]) = r.
We have shown that f([x]) = f([x^\prime]) whenever x \equiv x^\prime \pmod{7} i.e., f is well-defined.
Well-defined Function with domain as Quotient Set
Through the above example we have shown that in order to have a well-defined function, f : X\!/\!\!\sim \,\rightarrow Y\!, it must be the case that f([x]) = f([x^\prime]) whenever x \sim x^\prime for any x, x^\prime \in X.
A typical argument for verifying that a function, f : X\!/\!\!\sim \,\rightarrow Y\!, is well defined is as follows.
We take some arbitrary elements x, x^\prime \in X such that x \sim x^\prime and show that the proposed expressions for f([x]) \text{ and } f([x^\prime]) result in the same element in Y. In such a case, we can say that the proposed expression for f([x]) depends only on the equivalence class of x and not on the representative x itself and hence, the function, f, is well-defined.
Theorem
Let \sim be an equivalence relation on X. The necessary and sufficient condition for the binary relation, f : X\!/\!\!\sim \,\rightarrow Y\!, to be a (well-defined) function is that f([x]) = f([x^\prime]) whenever x \sim x^\prime for any x, x^\prime \in X.
Suppose f : X\!/\!\!\sim \,\rightarrow Y\!, is a binary relation such that f([x]) = f([x^\prime]) whenever x \sim x^\prime for any x, x^\prime \in X. We will prove that f is a (well-defined) function.
The binary relation, f, over sets X\!/\!\!\sim \text{ and } Y, that is, f \subseteq (X\!/\!\!\sim) \times Y is defined as
f = \{([x], y) : [x] \in X\!/\!\!\sim \wedge \,\, y \in Y\}We will prove that the binary relation f over sets X\!/\!\!\sim \text{ and } Y is a function.
From the definition of f we can see that for every [x] \in X\!/\!\!\sim there is a y \in Y such that ([x], y) \in f.
For the uniqueness assertion, suppose that ([x], y) \in f \text{ and } ([x^\prime], y^\prime) \in f such that [x] = [x^\prime].
Since [x] = [x^\prime] it follows that x \in [x^\prime] and hence, by definition of equivalence class x \sim x^\prime.
Therefore, f([x]) = f([x^\prime]) and since y = f([x]) \text{ and } y^\prime = f([x^\prime]), it implies that y = y^\prime.
Therefore, by definition of a function, the binary relation f over sets X\!/\!\!\sim \text{ and } Y is a function.
Suppose f : X\!/\!\!\sim \,\rightarrow Y is a well-defined function. We have to prove that f([x]) = f([x^\prime]) whenever x \sim x^\prime for any x, x^\prime \in X.
Suppose x \sim x^\prime for some arbitrary x, x^\prime \in X. Then, by definition of equivalence class, [x] = [x^\prime].
Since f : X\!/\!\!\sim \,\rightarrow Y is a well-defined function, whenever [x] = [x^\prime] it must be the case that f([x]) = f([x^\prime]).
Hence, we have proved the theorem.
Ternary Relation
Suppose we have a set of men, M, a set of women, W and a set of children, C. A possible relation, R, between these sets could be defined as “x \text{ is the child of } y \text{ and } z” . This would result in R being a set of 3\text{-tuples} also called triples such that each triple in R will have a child from set C associated with a father from set M and a mother from set W.
The set R could therefore be viewed as a subset of the Cartesian product of the three sets C, M \text{ and }W denoted by C \times M \times W, which is the set of all ordered triples (c, m, w) where c belongs to set C, m belongs to set M and w belongs to set W. Therefore, R \subseteq C \times M \times W.
A ternary relation, R, over the sets X, Y \text{and } Z is a new set of ordered triples (x, y, z) consisting of elements x from X, y from Y and z from Z. That is, elements x, y \text{ and } z are related if and only if the triple (x, y, z) belongs to the set of ordered triples that defines the ternary relation.
It should be noted that the ternary relation, R, over the sets X, Y \text{and } Z can be defined solely as a set of ordered triples (x, y, z) where x \in X, y \in Y and z \in Z, without specifying the underlying relationship between x, y \text{ and } z.
Definition
A ternary relation R over sets X_1, X_2 \text{ and } X_3 is a subset of the Cartesian product X_1 \times X_2 \times X_3.
That is, R \subseteq X_1 \times X_2 \times X_3.
The set X_i is called the ith domain of R i.e., the sets X_1, X_2 \text{ and } X_3 are the first, second and third domains, respectively, of R.
The statement (x_1, x_2, x_3) \in R reads “x_1, x_2, x_3 are R-related” and are denoted using prefix notation by Rx_1x_2x_3 and using postfix notation by x_1x_2x_3R. (A prefix notation is a type of mathematical notation in which the operators precede their operands, while in the postfix notation the operators follow their operands.)
When X_1 = X_2 = X_3, a ternary relation is called a homogeneous relation or endorelation.
In a ternary relation, the ordering of elements is important. That is, if x_1 \neq x_2 \neq x_3 then Rx_2x_3x_1 can be true or false independently of Rx_1x_2x_3. For example, 16 is divisible by 2 \text{ and } 4 but 2 is not divisible by 4 \text{ and } 16. Therefore, (16, 2, 4) \neq (2, 4, 16).
Types of Ternary Relations
The following are some types of ternary relations we will encounter during our study of mathematics.
Binary Function
A binary function, denoted by f, is a special type of ternary relation over sets X, Y \text{ and } Z that satisfies the following conditions :
- For every x \in X \text{ and } y \in Y there exists z \in Z such that (x, y, z) \in f
- (x, y, z) \in f \text{ and } (x, y, z^\prime) \in f imply that z = z^\prime
We usually denote (x, y, z) \in f as f(x, y) = z.
Also, since f is a ternary relation over sets X, Y \text{ and } Z it is a subset of the Cartesian product X \times Y \times Z i.e., f \subseteq X \times Y \times Z which is usually written as f : X \times Y \rightarrow Z, where X \times Y is the Cartesian product of X \text{ and } Y.
For example, if \mathbb{Z} is the set of integers, \mathbb{Z}^+ is the set of positive integers and \mathbb{Q} is the set of rational numbers, then division is a binary function f : \mathbb{Z} \times \mathbb{Z}^+ \rightarrow \mathbb{Q}. (A rational number is any number that can be written in the form \dfrac{p}{q}, where p is an integer and q is a nonzero integer.)
Binary Operation
The binary operation, denoted by f, on the set X is a binary function over the set X.
Since f is a homogeneous ternary relation over the set X, it is a subset of the Cartesian product X \times X \times X i.e., f \subseteq X \times X \times X which is usually written as f : X \times X \rightarrow X, where X \times X is the Cartesian product of X \text{ and } X.
For example, the binary function + : \mathbb{Z} \times \mathbb{Z} \rightarrow \mathbb{Z} over the set of integers \mathbb{Z} is a binary operation because the sum of two integers is an integer.
The element +(x, y) \in \mathbb{Z} is usually written as x + y.
Mathematical Structure
A mathematical structure is a non-empty set of mathematical objects, along with a specified collection of relations and functions defined on those objects, and a set of distinguished constants that are elements of that set. These components are determined by an irreducible set of axioms that function as the generative rules defining the permissible operations and the resultant relationships within the structure.
A common way to represent a mathematical structure is as a tuple (Set, Operations/Functions, Relations, Constants).
Note: While the most significant and deeply studied mathematical structures are governed by such axiomatic foundations, it is conceivable to consider mathematical structures in a broader sense where the specified components might not be explicitly determined by a formal and irreducible set of axioms. However, the power and utility of mathematical structures in building consistent and coherent theories often arise from their axiomatic underpinnings.
Examples
The Structure defined by Second-Order Peano Axioms
The Peano axioms define a fundamental mathematical structure (\mathbb{N}_0, S, 0) involving:
- A non-empty set of objects: The set of natural numbers, \mathbb{N}_0 = \{0, 1, 2, 3, \dots\}.
- A distinguished constant: The natural number 0 \in \mathbb{N}_0.
- A function: The successor function S : \mathbb{N}_0 \rightarrow \mathbb{N}_0, where S(n) is intuitively the next natural number after n in the sequence of natural numbers. This function defines a fundamental operation on the natural numbers.
- Relations (defined by the axioms themselves): The Peano axioms themselves define crucial relations and properties within this structure:
- Equality (=): Assumed as a fundamental logical relation.
- Injectivity of the Successor Function: \forall m, n \in \mathbb{N}_0, (S(m) = S(n) \implies m = n). This defines a specific property of the successor function as a relation between natural numbers and their successors.
- 0 is not a Successor: \forall n \in \mathbb{N}_0, (S(n) \neq 0). This defines a relationship between 0 and the range of the successor function.
- The Induction Axiom (Second-Order): This axiom ensures the minimality of the set of natural numbers i.e., the set \mathbb{N}_0 consists of only the standard natural numbers that we know of and no other extraneous elements.
This powerful axiom provides a method for proving statements about the entire set of natural numbers. It states that if a subset T \text{ of } \mathbb{N}_0 contains 0, and if for every n \text{ in } T, its successor S(n) is also in T, then T must be the set of natural numbers i.e., T = \mathbb{N}_0. In essence, if a property holds for 0 and is preserved by the successor function, it holds for all natural numbers.
- Equality (=): Assumed as a fundamental logical relation.
For a more detailed explanation of the Peano axioms and the structure they define, you can refer here.
The Structure of the Real Numbers
Consider the set of real numbers, \mathbb{R}. We can define a mathematical structure (\mathbb{R}, +, \times, <, 0, 1) on this set by including:
- A non-empty set of objects: The set of real numbers, \mathbb{R}.
- Relations: The order relation “<” (less than), which is a binary relation on \mathbb{R}.
- Functions: The binary operations of addition “+” and multiplication “\times", which are functions from \mathbb{R} \times \mathbb{R} to \mathbb{R}.
- Distinguished constants: 0 (the additive identity element in \mathbb{R} i.e., a + 0 = a, for any real number a) and 1 (the multiplicative identity element in \mathbb{R} i.e., a \times 1 = a, for any real number a).
The operations and the order relation in this structure are determined by a fundamental set of axioms, including the field axioms (defining the properties of addition and multiplication) and the order axioms (defining the properties of the “less than” relation). Crucially, the real numbers are also characterized by the completeness axiom (often stated as the least upper bound property or Dedekind completeness), which ensures that every non-empty subset of \mathbb{R} that is bounded above has a least upper bound within \mathbb{R}. This axiom distinguishes the real numbers from the rational numbers, which do not satisfy it.
Examples of Other Mathematical Structures
Beyond these examples, the concept of a mathematical structure provides a unifying framework across diverse areas of mathematics. In mathematics, many specific types of structures are studied in detail, each with its own defining axioms and properties, such as groups (equipped with a single associative binary operation, an identity element, and inverses), rings (with two binary operations satisfying certain axioms), fields (which are commutative rings with multiplicative inverses for non-zero elements), and topological spaces (where the notion of “nearness” is formalized).
Isomorphism
A fundamental idea in the study of mathematical structures is that of isomorphism. Two mathematical structures are said to be isomorphic if they are of the same type (i.e., they satisfy the same defining axioms and have corresponding basic components) and there exists a structure-preserving bijection between their underlying sets. Intuitively, isomorphic structures are considered to be essentially the same, differing only in the names of their elements.
Model Theory
The formal framework for studying mathematical structures, including their types and isomorphisms, is provided by model theory, a branch of mathematical logic that rigorously investigates the relationship between formal axiomatic theories and their interpretations, known as models. These models are, in essence, the mathematical structures that satisfy the axioms of a given theory, providing a deep and abstract perspective on the foundations of mathematics.
To illustrate this connection, consider Peano’s Axioms, which form a formal theory about the natural numbers. The formal language of Peano Arithmetic uses abstract symbols to represent the natural numbers, including the constant symbol 0, the unary function symbol S, variables like n, m, x, y, and logical symbols such as \forall, \exists, \text{ and } =. The standard structure of the natural numbers (\mathbb{N}_0, S, 0), where \mathbb{N}_0 is the set of natural numbers, S is the successor function, and 0 is zero, serves as a model for these axioms because the model gives these symbols concrete meaning. For example, the constant symbol “0" refers to the number zero itself, the function symbol “S" refers to the successor function, the symbols “\forall " and “\exists " mean “for all” and “there exists” when quantifying over the natural numbers, and the symbol “=” represents the actual equality relationship between natural numbers. Under this interpretation, all the axioms of Peano Arithmetic are true in the structure (\mathbb{N}_0, S, 0).