authored by Premmi and Beguène
This is a refresher on some basic concepts in probability theory which are often encountered while studying cryptography. We have deliberately tried to keep the discussion simple and hence will not be discussing Sigma Algebra, measurable space, probability measure etc.
Introduction
Since cryptography is about building secure systems, we need a fail proof way to assess an adversary’s chance of breaking the system. We would like to know what is the chance that someone can guess the private key of a bitcoin address, the secret key of a digital signature, decipher an encrypted message etc.
In order to quantify this “chance” in a robust way, we need a logical framework to measure uncertainty and randomness in a systematic way.
Ideally, we design an experiment that models the problem we are trying to solve. This experiment has a set of known outcomes and the likelihood of each of these outcomes occurring is also known. Before the experiment is conducted it is unknown which outcome will occur and hence the uncertainty. One of the possible outcomes gets materialized only after the experiment is performed.
Consider a simple experiment of rolling a fair 6-sided die. This experiment has an outcome of 1, 2, 3, 4, 5 \text{ or } 6. Since each of these outcomes is equally likely, the likelihood of rolling a particular number is \dfrac{1}{6}. Now we can answer some questions like the likelihood of landing a number greater than 4 or less than 3 etc.

The study of probability helps us measure these “likelihoods” in a mathematically precise way.
Definition of Sample Space and Event
Annie, a little poppet, has a box of toys consisting of 3 bears and 3 cars, in 3 colors namely blue, yellow and brown. Everyday she pulls out a toy at random from the box and plays with it.
What is the likelihood that she will pull out a bear? What is the chance that she plays with a blue toy?
In order to answer these questions, we define an experiment which comprises of Annie pulling out a toy from the box; since she pulls out a toy at random and the toys are arranged such that each toy is equally likely to be picked by her, the outcome of this experiment is equally likely to be any one of the six toys i.e., the likelihood of Annie pulling out a particular toy is \dfrac{1}{6}. Below is a pictorial representation of the experiment and its possible outcomes.
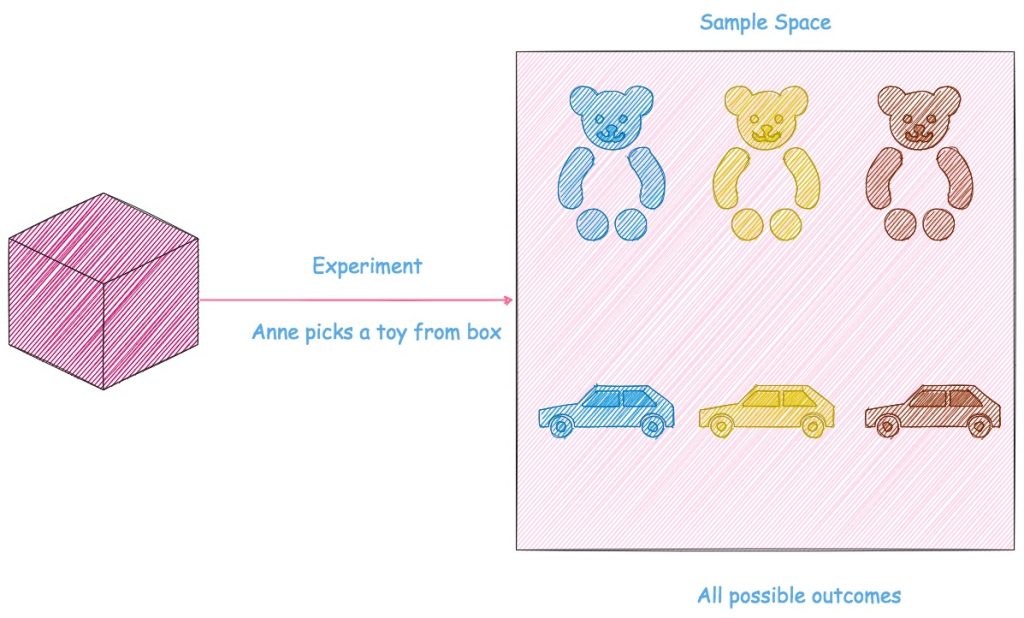
The sample space S of an experiment is the set of all possible outcomes of the experiment. In our case,
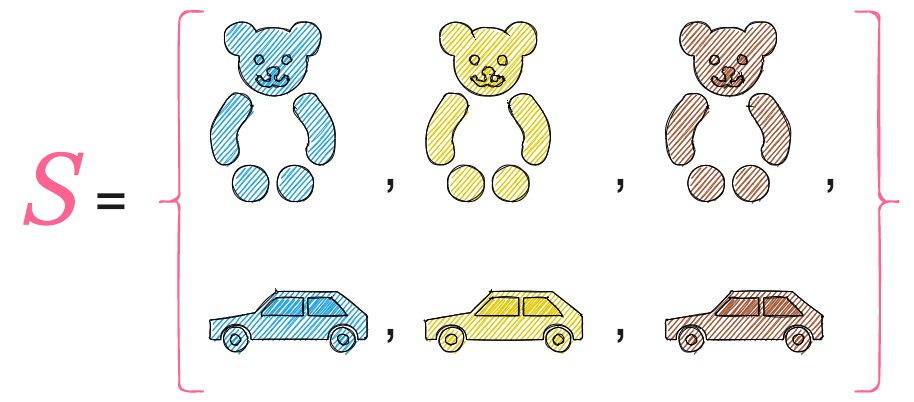
Now that we have defined our experiment and the sample space, let us start answering the questions that we posed earlier.
In order to calculate the likelihood of Annie pulling out a blue toy, let us define a subset A, of the sample space S, which comprises of outcomes of the experiment which result in a blue toy i.e.,
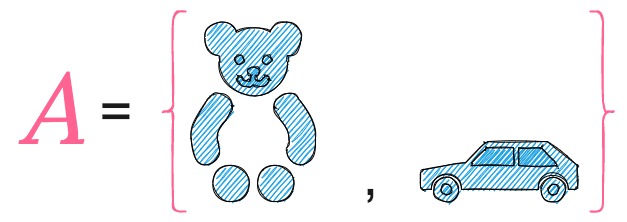
The likelihood of A denotes the likelihood of Annie picking a blue toy; this can happen in two ways, when Annie pulls out a blue bear or a blue car. Since the likelihood of pulling out a toy is \dfrac{1}{6}, and the set A has two toys, the likelihood of A is 2 \times \dfrac{1}{6} = \dfrac{1}{3}.
By similar reasoning, to find the likelihood of Annie pulling out a bear, we define a subset B, of the sample space S, which comprises of the outcomes of the experiment which result in a bear i.e.,
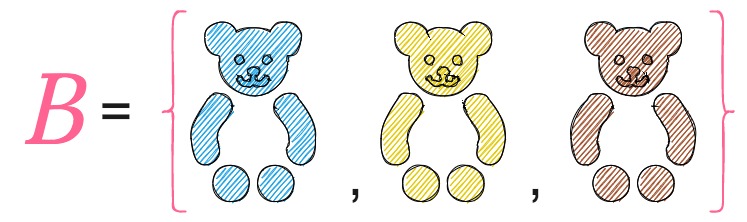
The likelihood of B denotes the likelihood of Annie picking a bear; Since the set B has three toys (or three possible outcomes), the likelihood of B is 3 \times \dfrac{1}{6} = \dfrac{1}{2}.
A and B, which are subsets of the sample space S, are called events. When we say that an event A has occurred, we mean that the outcome of the experiment is in A. In this case, the outcome of the experiment is either a blue bear or a blue car.
Cardinality of Sample Space S
The sample space S of an experiment is called countable if it is finite or countably infinite, otherwise it is called uncountable (also called uncountably infinite).
Countable Set
A set S is countable if :
- Its cardinality |S| (the number of elements in the set) is less than or equal to \aleph_0, the cardinality of the set of natural numbers \mathbb{N}, where \mathbb{N} = \{1, 2, 3, \ldots\}.
- There exists an injective function (or a one-to-one function i.e., every element of the function’s codomain is the image of at most one element of its domain) \mathcal{f} from S \text{ to } \mathbb{N} i.e., \mathcal{f} : S \rightarrow \mathbb{N}.
- S is empty or there exists a surjective function (or onto function i.e., every element of the function’s codomain is the image of at least one element in its domain) \mathcal{f} from \mathbb{N} \text{ to } S i.e., \mathcal{f : \mathbb{N} \rightarrow }S.
- There exists a bijective (one-to-one and onto) mapping between S and a subset of \mathbb{N}.
- S is either finite (|S| < \aleph_0) or countably infinite (|S| = \aleph_0).
All of the above definitions are equivalent.
Finite Set
A set S is finite if there exists a bijection f : \big\{1, 2, \ldots , n\big\} \rightarrow S for some n \in \mathbb{N} (set of all positive integers).
A bijection is a relation between two sets such that each element of either set is paired up with exactly one element of the other set, i.e., a one-to-one correspondence between domain and co-domain.
The number n is the cardinality of set S i.e., |S| = n. The empty set (the unique set having no elements) \{\} \text{ or } \emptyset is considered finite with cardinality zero.
Countably infinite Set
A set S is countably infinite if :
- Its cardinality |S| is exactly \aleph_0.
- There is an injective and surjective (and therefore bijective) mapping between S \text{ and } \mathbb{N}.
Uncountable Set
A set S is uncountable if :
- Its cardinality is neither less or equal to \aleph_0, the cardinality of the set of natural numbers \mathbb{N}.
- Its cardinality is strictly greater than \aleph_0 i.e., |S| > \aleph_0.
- There exists no injective function from S to \mathbb{N}.
- S is nonempty and here exists no surjective function from \mathbb{N} to S.
- There exists no bijective mapping between S and \mathbb{N}.
All of the above definitions are equivalent.
Example of a Finite Sample Space
Consider the experiment of tossing two fair coins. The sample space S (possible outcomes) of this experiment is given by, S = \big\{ HH, HT, TH, TT \big\} , where ‘H’ denotes ‘Heads’ and ‘T’ denotes ‘Tails’. Here, n=4 and
f:\{1, 2, 3, 4\} \rightarrow \{HH, HT, TH, TT\}.The sample space is said to be finite since there is a one to one mapping between the four integers and the outcomes of the sample space.
Example of a Countably Infinite Sample Space
Let us consider the experiment of tossing a fair coin till a head appears. The sample space S of this experiment is given by, S = \big\{ H, TH, TTH, TTTH, \ldots \big\} , where ‘H’ denotes ‘Heads’ and ‘T’ denotes ‘Tails’. Every positive integer can be mapped to an element in the sample space as shown below.
1 \rightarrow H, 2 \rightarrow TH, 3 \rightarrow TTH, 4 \rightarrow TTTH\cdots
Since there exists a bijective mapping between S and \mathbb{N}, the set of all positive integers, S is countably infinite.
Example of an Uncountable Sample Space
Suppose we conduct an experiment measuring the weight of a man in kilograms on a particular day. The sample space S is the set of all positive real numbers in the interval \big[45, 250\big] i.e., S = \big\{ s \in \mathbb{R}\, |\, 45 \leq s \leq 250 \big\}. We can use Cantor’s diagonal argument to prove that this set is uncountable because for any list of numbers in the interval \big[45, 250\big], there will always be numbers in \big[45, 250\big] that are not on the list.
For example, suppose we construct a list of numbers between \big[45, 250\big] as \big[45, 45.5, 46, 46.5, \ldots, 250\big], we can always construct another list \big[45, 45.1, 45.2, \ldots, 46.1, 46.2, \ldots, 250\big] that has numbers not included in the previous list.
Also if an uncountable set X is a subset of a set Y, then Y is uncountable as well. Since we have shown that the set of all positive real numbers in the interval \big[45, 250\big] is uncountable, it follows that the set \mathbb{R} of all real numbers is uncountable as well.
Equivalently, the set S is uncountable or uncountably infinite since there is no bijective mapping between S and the set of all positive integers, \mathbb{N}. Also, the cardinality of set S is strictly greater than \aleph_0, the cardinality of the set of all positive integers.
Definition of Discrete Sample Space
A sample space S is called discrete if S is countable i.e., S is finite or countably infinite.
Definition of Continuous Sample Space
A sample space S is called continuous if S is uncountable.
Definition of Probability
A probability space consists of a sample space S and a probability function P which takes an event A\subseteq S as input and returns P(A), a real number between 0 and 1, as output.
P(A) is the mathematical term for the “likelihood of A” that we had discussed previously.
The function P must satisfy the following axioms:
- P(\emptyset) = 0, \, P(S) = 1
- If A_1, \, A_2, \, \ldots are disjoint events, then
P \Big(\underset{j\,=\,1}{\overset{\infty}{\cup}}A_j\Big) = \underset{j \,= \, 1}{\overset{\infty}{\sum}}\, P(A_j).Disjoint events means that the events are mutually exclusive : A_i \cap A_j = \emptyset for i \neq j.
Note:
\emptyset denotes an empty set i.e., a set with no elements in it.
Union of n events A_1, \ldots, A_n, denoted by A_1 \cup A_2 \cdots \cup A_n, is the occurrence of at least one of the events A_1, \ldots, A_n.
Intersection of two events A \text{ and } B, denoted by A \cap B, is the simultaneous occurrence of both the events A \text{ and } B. Similarly, for n events, A_1 \cap A_2 \ldots \cap A_n, denotes the simultaneous occurrence of all the n events.
Let us represent these axioms pictorially, in the context of the experiment in which Annie picks up a toy at random from a box.
Since the sample space S represents all possible outcomes of the experiment,
P(S) = P(Blue\, Bear) + P(Yellow\, Bear) + P(Brown\, Bear) + P(Blue\, Car) + P(Yellow\, Car) + P(Brown\, Car)
Since Annie picks a toy at random, each outcome is equally likely; hence,
P(Blue\, Bear) = P(Yellow\, Bear) = P(Brown\, Bear) = P(Blue\, Car) = P(Yellow\, Car) = P(Brown\, Car)
\begin{equation*}
\begin{split}
P(S) & = P(Blue\, Bear) + P(Blue\, Bear) + P(Blue\, Bear) + P(Blue\, Bear) + P(Blue\, Bear) + P(Blue\, Bear) \\
& = 6 \times P(Blue \, Bear)
\end{split}
\end{equation*} Since as per the first axiom, P(S) = 1, i.e., the probabilities of all the outcomes in the sample space should sum to 1,
\begin{equation*}
\begin{split}
P(Blue \, Bear) & = \frac{P(S)}{6} \\
& = \frac{1}{6}
\end{split}
\end{equation*} Hence,
P(Blue\, Bear) = P(Yellow\, Bear) = P(Brown\, Bear) = P(Blue\, Car) = P(Yellow\, Car) = P(Brown\, Car) = \frac{1}{6}The pictorial representation of each outcome of the sample space S is shown on top of a line segment, whose length equals the probability of that particular outcome occurring. Since, as per the first axiom, P(S) = 1, the summation of the lengths of all the line segments, where each segment’s length represents the probability of a particular outcome occurring, equals 1.
To illustrate the second axiom, let us define define two events,
A_1 = \{Blue\, Bear\} and A_2 = \{Blue\, Car, Yellow\, Car, Brown\, Car\}, where A_1 denotes the event that occurs when Annie picks a blue bear and A_2 denotes the event that occurs when Annie picks a car.
Since a toy cannot be both a bear and a car, A_1 and A_2 are disjoint events, i.e., A_1 \cap A_2 = \emptyset.
Let us calculate the probabilities of each of the events A_1 and A_2 occurring.
\begin{equation*}
\begin{split}
P(A_1) & = P(Blue\, Bear) \\
& = \frac{1}{6}
\end{split}
\end{equation*} Annie can pick a car in three ways i.e., she can pick a car by either picking a blue, yellow or brown car. Hence the event A_2 can occur in three possible ways and so comprises of three possible outcomes. Since the probability of each outcome is \dfrac{1}{6}, the total probability of the entire event A_2 is
\begin{equation*}
\begin{split}
P(A_2) &
= P(Blue\, Car) + P(Yellow\, Car) + P(Brown\, Car) \\
& = \frac{1}{6} \,+ \frac{1}{6} \,+ \frac{1}{6} \\
& = \frac{3}{6} \\
& = \frac{1}{2}
\end{split}
\end{equation*} Let us calculate the probability of Annie picking either a blue bear or a car i.e., the probability of event A_1 or A_2 occurring, which is denoted by, P(A_1 \cup A_2).
By the second axiom,
\begin{equation*}
\begin{split}
P(A_1 \cup A_2) & = P(A_1) + P(A_2) \\
& = \frac{1}{6} + \frac{3}{6} \\
& = \frac{4}{6} \\
& = \frac{2}{3}
\end{split}
\end{equation*} The second axiom is graphically represented below.

Conditional Probability
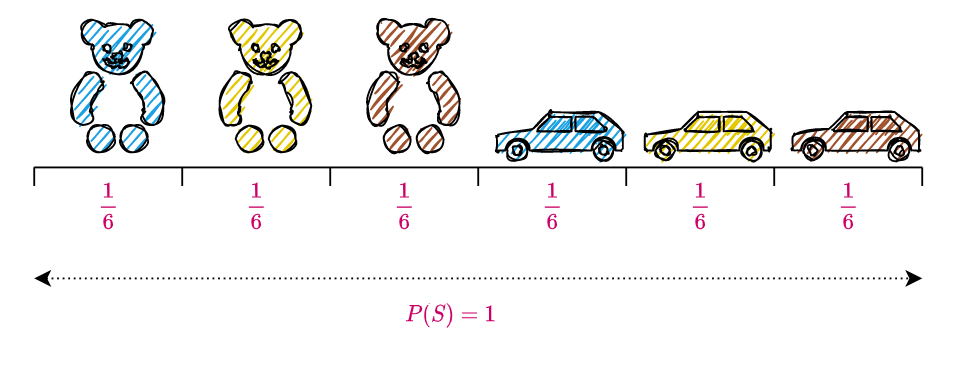
Let us develop some intuition for conditional probability by revisiting the experiment in which little poppet Annie picks a toy from her box.
The sample space S of the experiment together with the events A \text{ and } B are pictorially represented below.

Suppose we get to know that Annie has picked a bear, what is the probability that it is a blue bear? Reframing this question in the probabilistic framework, what is the probability of event A (Annie picks a blue toy) occurring, given that event B (Annie picks a bear), has occurred? This is represented symbolically as P(A\,|\,B).
Since we know that Annie picked a bear i.e., event B occurred, we get rid of all the outcomes in B^c (the set of elements not in B), since it is incompatible with the knowledge that B occurred. All the outcomes in B^c are greyed out in the figure below. From the figure we can see that there is only one outcome remaining in A and its probability is given by P(A \cap B) = \frac{1}{6}. So the probability that Annie picked a blue bear i.e.,
P(A\,|\,B) = \frac{P(A \,\cap\, B)}{P(B)}
= \frac{\frac{1}{6}}{\frac{3}{6}}
= \frac{1}{6} \times \frac{6}{3}
= \frac{1}{3}
The calculation of P(A\,|\, B) is pictorially represented below.
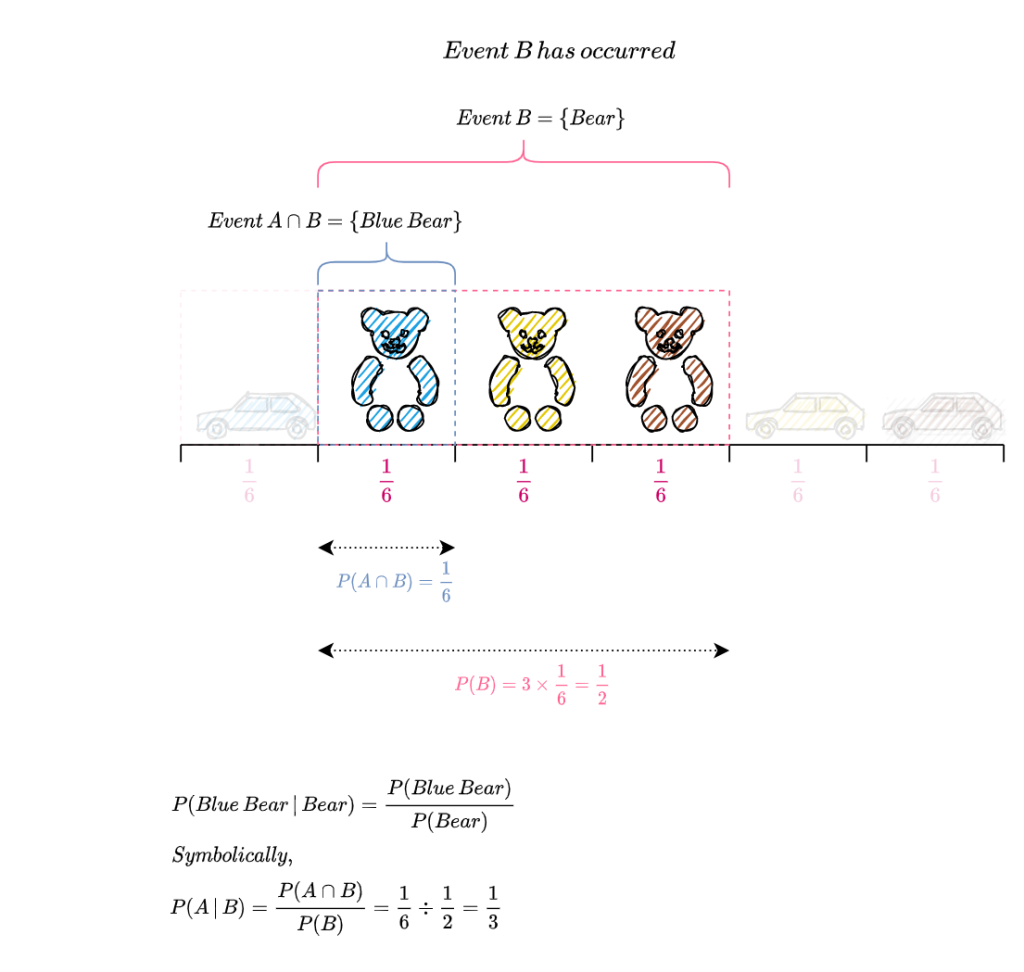
Since B has occurred, we must calculate the probability of all outcomes with respect to B. So B becomes the new sample space and as per the first axiom of probability, P(B) must equal 1. From the above diagram, we can see that P(B) = \frac{1}{2}. So we need to renormalize P(B) so that it sums to 1 while keeping the proportion of the probability of each outcome in B with respect to the probability of B the same. How do we do this?
The figure below illustrates how to increase the length of a stick from \frac{1}{2} unit to 1 unit while maintaining the proportion of its individual divisions.
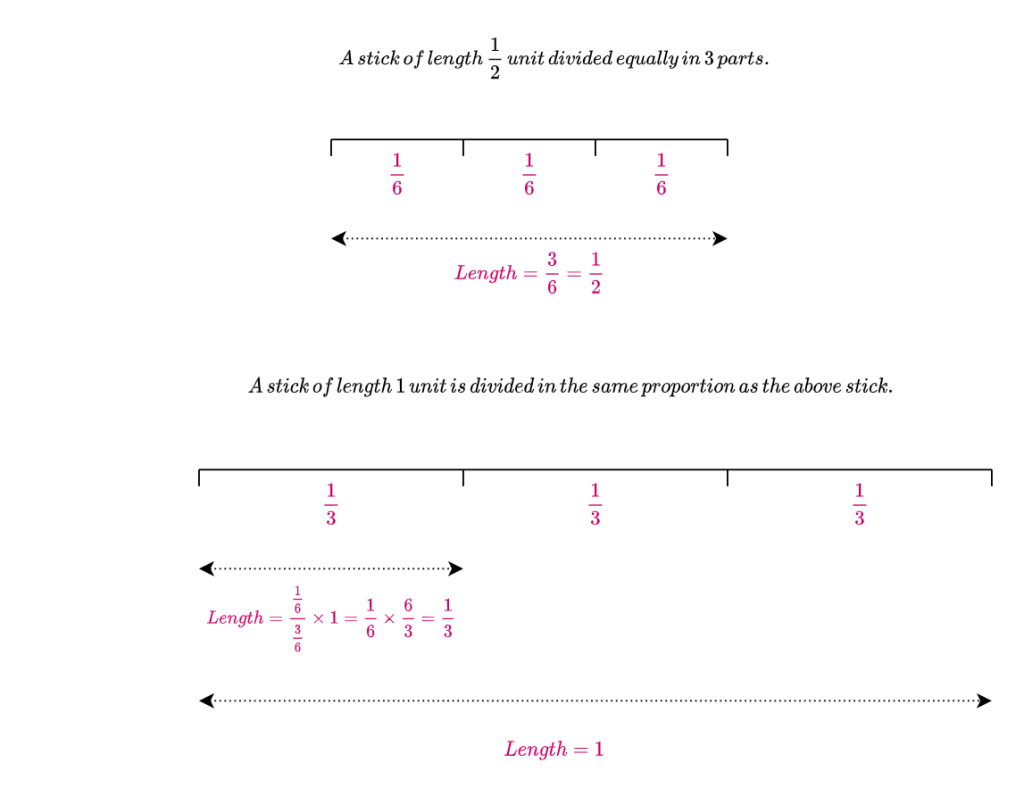
The figure below shows the renormalization of P(B) so that it sums to 1.

We can see that after renormalization,
P(A\,|\,B) = \frac{P(A \,\cap\, B)}{P(B)}
= \frac{\frac{1}{3}}{1}
= \frac{1}{3}Why is P(A\,|\,B) = \frac{1}{3} irrespective of whether P(B) = \frac{1}{2} or P(B) = 1 ? Since P(A\,|\,B) is the ratio between P(A \cap B) and P(B), this ratio does not change when P(B) is proportionally scaled.
Let us consider a more mundane example to illustrate this point. Suppose George weighs 50 kgs and Jamie weighs 100 kgs, the ratio of the weight of George to Jamie is \frac{50}{100} = \frac{1}{2}. Now suppose instead of kgs we measure their weight in pounds, the ratio of their weights would still remain the same i.e., Jamie’s weight will still be double of George’s. Lets verify this by calculation. Since 1 kg = 2.20462 pounds, the ratio of their weights is \frac{50 \times 2.20462}{100 \times 2.20462} = \frac{1}{2}.
In our case, when P(B) = \frac{1}{2}, P(A\,|\,B) = \frac{\frac{1}{6}}{\frac{1}{2}} = \frac{1}{3} and when P(B) = 1, P(A\,|\,B) = \frac{\frac{1}{6} \times 2}{\frac{1}{2} \times 2} = \frac{\frac{1}{6}}{\frac{1}{2}} = \frac{1}{3}.
From this discussion on conditional probability, it is obvious that whenever we calculate the probability of an outcome or an event it is always with respect to a sample space. So when we calculated P(A) i.e.,the probability of Anne picking a blue toy we actually calculated P(A \,|\, S). This is illustrated in the figure below.

It should be noted that conditional probabilities are still probabilities and so they must satisfy the axioms of probability.
Definition of Conditional Probability
If A \text{ and } B are events in a sample space S, with P(B) > 0, then the conditional probability of A given B, denoted by P (A\,|\,B) , is defined as,
P(A\, |\,B) = \frac{P(A\cap B)}{P(B)} P(A\,|\,B) is the probability of an event A occurring, given that the event B has occurred i.e., we want to update the probability of event A occurring in light of the new evidence that event B has occurred. We call P(A) the prior probability of A and P(A\,|\,B) the posterior probability of A (“prior” means before updating based on the evidence, and “posterior” means after updating based on the evidence).
Probability of the Intersection of Two Events
For any events A \text{ and } B with positive probabilities,
P(A \cap B) = P(B)\, P(A \,|\, B) = P(A)\, P(B \,|\,A).
This follows from taking the definition of conditional probability i.e., P(A\,|\,B) = \dfrac{P(A \,\cap\, B)}{P(B)} and multiplying both sides by P(B), to get P(A \cap B) = P(B)\, P(A \,|\, B).
Similarly by taking the definition of conditional probablility as P(B\,|\,A) = \dfrac{P(A \,\cap\, B)}{P(A)}and multiplying both sides by P(A) we get P(A \cap B) = P(A)\, P(B \,|\, A).
From the definition of conditional probability, P(A\,|\,B) = \dfrac{P(A \,\cap\, B)}{P(B)} and the probability of the intersection of two events, P(A \cap B) = P(A)\, P(B \,|\, A), it follows that,
P(A\,|\,B) = \frac{P(A)\, P(B \,|\,A)}{P(B)}.This result which relates P(A\,|\,B) to P(B\,|\,A) is called Bayes’ Theorem.
Independence of Events
When events provide no information about each other, they are said be to independent.
Independence of Two Events
Events A \text{ and } B are independent if and only if P(A\cap B) = P(A) P(B).
Let us assume that A and B are independent events i.e., P(A\cap B) = P(A) P(B), with P(A) > 0 and P(B) > 0.
By the definition of conditional probability,
\begin{equation*}
\begin{split}
P(A\,|\,B) & = \frac{P(A \,\cap\, B)}{P(B)} \\
& = \frac{P(A)\,P(B)}{P(B)} \; \\
& = P(A).
\end{split}
\end{equation*} Similarly P ( B \,|\, A ) = P(B) .
Intuitively, if A \text{ and } B are independent, then learning that B has occurred provides us with no information whether or not A has occurred (and vice versa).
Random Variable
Definition
Given an experiment with sample space S, a random variable X is a function that maps the sample space S to the real numbers \mathbb{R} i.e., X: S \rightarrow \mathbb{R}.
By convention, a random variable is usually denoted by capital letters X, Y, Z and its values by lower case letters x, y, z.
A random variable X assigns a numerical value X(s) to each possible outcome s of the experiment. Each outcome of the experiment could be mapped to the same numerical value.
The random variable X is a numerical summary of some aspect of the experiment.
The source of randomness for X is the experiment itself, in which a sample outcome s \in S is chosen according to a probability function P. Before we perform the experiment, the outcome s has not yet been realized, so we don’t know the value of X. Once the experiment is completed and the outcome s is known, X crystallizes into the numerical value X(s).
As an example, consider an experiment where we toss a fair coin thrice. The sample space consists of eight possible outcomes : S = \{ HHH, HHT, HTH, THH, HTT, THT, TTH, TTT \}.
Let X be the number of heads. This is a random variable with 0, 1, 2 and 3 as possible values. In terms of the function notation, X assigns the value 0 to the outcome TTT, 1 to the outcomes HTT, THT \text{ and } TTH, 2 to the outcomes HHT, HTH \text{ and } THH and 3 to the outcome HHH. That is,
X (TTT) = 0
X (HTT) = X (THT) = X (TTH) = 1
X ( HHT) = X (HTH) = X (THH) = 2
X (HHH) = 3
We can define any number of random variables on the same sample space, each numerically summarizing a different aspect of an experiment.
Let Y be the number of tails. Since X + Y = 3 , in terms of X, we have Y = 3 - X.
Y(s) = 3 - X(s)
In the above example X and Y are two random variables defined on the same sample space though X denotes the number of heads and Y the number of tails that result when a fair coin is tossed thrice.
The following figure graphically represents the mapping of the sample space S to the real line by the random variable X, which denotes the number of heads and the random variable Y, which denotes the number of tails that result in an experiment where we toss a fair coin thrice. The random variables, X and Y, are defined on the same sample space S, though they summarize different aspects of the experiment. While random variable X maps the outcome s_1, namely, that of the three tosses of the fair coin resulting in heads, to 3, the random variable Y maps the same outcome s_1 to 0, since it represents the number of tails that occur in three tosses of a fair coin.
Types of Random Variable
There are two main types of random variables, namely, discrete random variables and continuous random variables.
Discrete Random Variable
A discrete random variable X is a function that maps a discrete sample space S (this means S is countable i.e., either finite or countably infinite) to the real numbers \mathbb{R}. Specifically, to each element s\in S, we assign the real number X(s). So the possible values of a discrete random variable form a countable set.
If X is a discrete random variable, then the finite or countably infinite set of values x such that P(X = x) > 0 is called the support of X. Usually in applications, the support of a discrete random variable is a set of positive integers.
Examples of Discrete Random Variable
Following are some examples of discrete random variables :
- The number of applicants for a job.
- The number of girls in a randomly selected two-child family.
- The number of heads in two tosses of a coin.
- The number of customers arriving at a bookstore between 7:00 p.m. and 9:00 p.m.
Continuous Random Variable
A continuous random variable can take any real value in an interval and its possible values form an uncountably infinite set.
Examples of Continuous Random Variable
Following are some examples of continuous random variables :
- The weight of refuse on a truck arriving at a landfill.
- The temperature of a cup of tea served at a restaurant.
- The air pressure of a tire on an automobile.
- The amount of rain recorded at an airport one day.
Note on random variables used in cryptography: Since in cryptography we mostly deal with finite sample spaces for example message space, key space etc we use discrete random variables to a large part. Hence the following discussion will pertain only to discrete random variables.
Distribution of a Discrete Random Variable
The distribution of a random variable specifies the probabilities of all events associated with the random variable. Say, for the random variable X denoting the number of girls in a randomly selected two-child family, the distribution enumerates the probability of X equaling 0, 1 \text{ or } 2. Using this distribution, we can calculate the probability that there is at least one girl child. The distribution helps us in answering questions about the probability that a random variable will fall within a given range or be greater or less than a particular value etc.
In our example, each of these numbers in the support of X namely 0, 1 \text{ or } 2 corresponds to an event in the sample space S = \{ GG, GB,BG, BB \} of equally likely outcomes. (‘G’ denotes a girl and ‘B‘ a boy). \{ X = 1 \} consists of the sample outcomes GB and BG which are the two outcomes to which X assigns the number 1. Since \{ GB, BG \} is a subset of the sample space, it is an event. Similarly, \{ X = 0 \} consists of the only sample outcome \{ BB \} to which X assigns the number 0 and \{ X = 2 \} consists of the only sample outcome \{ GG \} to which X assigns the value 2. The probability \{ X = 0 \} \text{ is } \frac{1}{4} (each outcome in the sample space is equally likely and there is only one outcome corresponding to this event.) Similarly, probability \{ X = 1 \} \text{ is } \frac{2}{4} = \frac{1}{2} and \{ X = 2 \} \text{ is } \frac{1}{4} . The probability that there is at least one girl child is the event \{X \geq 1\} i.e., X = 1 or X = 2 which is \frac{1}{2} + \frac{1}{4} = \frac{3}{4} (when two events are disjoint we add their probabilities).
Now that we have an understanding of the distribution of a discrete random variable, let us define it in a mathematical way.
For a discrete random variable, the most intuitive way to express its distribution is with a probability mass function.
Definition
Let X be a discrete random variable and let x_1, x_2, \ldots be the values which it assumes. The aggregate of all the outcomes s of the sample space S to which X assigns the number x_j forms the event X = x_j. This event is also written as \{X = x_j\}; formally, \{ X = x_j\} is defined as \{s \in S : X(s) = x_j\}, but writing \{ X = x_j\} is shorter and more intuitive. Its probability is denoted by P(X = x_j). The probability mass function (PMF) of a discrete random variable X is defined as the function p_X such that p_X(x_j) = P(X = x_j).
Clearly, p_X(x_j) \geq 0 (positive if x_j is in the support of X , 0 otherwise) and \Sigma \, p_X(x_j) = 1.
Let us construct the probability mass function of the random variable X denoting the number of girls in a randomly selected two-child family.
Since X equals 0 if BB occurs, 1 if GB or BG occurs, and 2 if GG occurs, the PMF of X is the function p_X given by,
p_X(0) = P(X = 0) = \frac{1}{4},
p_X(1) = P(X = 1) = \frac{1}{2},
p_X(2) = P(X = 2) = \frac{1}{4},
and p_X(x) = 0 for all the other values of x.
Functions of Random Variables
What does it mean to take a function of a random variable? A function g(X) of a random variable X is any function g that maps real numbers to real numbers i.e., g : \mathbb{R} \rightarrow \mathbb{R}.
A function of a random variable is also a random variable with its source of randomness being the experiment. We know that a random variable maps each outcome of an experiment s in the sample space S to a real number. Let X be a random variable defined on a sample space S with 6 outcomes namely s_1, s_2, \ldots, s_6. If we apply the function g to the numbers X(s_1) through X(s_6), we now have numbers g(X(s_1)) through g(X(s_6)) , which gives a new mapping from sample outcomes to real numbers and we have essentially created a new random variable, g(X) .
Thus if X is a random variable, then X^2, e^X and cos(X) are also random variables.
Suppose X is a random variable that denotes the number of heads that turn up when a fair coin is tossed thrice. Then g(X) = 3 - X is the number of tails resulting from three tosses of the coin. Since X is a random variable, g(X) is also a random variable; both deriving their source of randomness from the experiment of tossing the coin thrice whose outcome is unknown until the experiment is conducted.
Definition of Function of a Random Variable
For an experiment with sample space S, a random variable X, and a function g : \mathbb{R} \rightarrow \mathbb{R}, g(X) is the random variable that maps s to g(X(s)) for all s \in S.
Suppose g(X) = X^2, the figure below shows that g(X) is the composition of the functions X and g. If X crystallizes to 3, then g(X) crystallizes to 9.

The random variable X is defined on a sample space S with 8 outcomes, and has possible values 0, 1, 2 \text{ and } 3. The function g is the square function. Composing X and g gives the random variable g(X) = X^2, which has possible values 0, 1, 4 \text{ and } 9.
Independence of Random Variables
Intuitively, if two random variables X and Y are independent, then knowing the value of X gives us no information about the value of Y and vice versa.
Definition
Independence of Two Random Variables
Random variables X and Y are said to be independent if,
P(X \leq x, Y \leq y) = P(X \leq x)P(Y \leq y), \,\forall\, x, y \in \mathbb{R}.In the discrete case this is equivalent to the condition,
P(X = x, Y = y) = P(X = x)P(Y = y), \,\forall\, x \in X\, \text{and}\, y \in Y.Independence of Many Random Variables
Random variables X_1, \ldots, X_n are independent if,
P ( X_1 \leq x_1, \ldots, X_n \leq x_n ) = P ( X_1 \leq x_1 ) \ldots P (X_n \leq x_n), \forall x_1, \ldots , x_n \!\! \in \mathbb{R}. For infinitely many random variables, we say that they are independent if every finite subset of the random variables is independent.
Functions of Independent Random Variables
If X and Y are independent random variables, then any function of X is independent of any function of Y .
Conditional Independence of Random Variables
Random variables X and Y are conditionally independent given another random variable Z if for all x, y \epsilon \, \mathbb{R} and all z \in Z,
P(X \leq x, Y \leq y \,|\, Z = z) = P(X \leq x \,|\, Z = z)\, P(Y \leq y \,|\, Z = z).
For discrete random variables, the equivalent condition is
P(X = x, Y = y \,|\, Z = z) = P(X = x \,|\, Z = z)\,P(Y = y \,|\, Z = z).
Conditional Probability Mass Function
For any discrete random variables X and Y , the function P (X = x \,|\, Y = y) , when considered as a function of x for fixed y, is called the conditional probability mass function of X given Y = y .
Expectation
Intuitively, the expected value of a random variable can be thought of as the average of values attained by the random variable in repeated trials of the experiment.
Consider the experiment of tossing a fair coin twice. Let X be the number of heads. We perform this experiment n times, where n is a very large number, and note down the value realized by X each time. If we take the arithmetic mean of all the numbers observed (add all the numbers and divide by n), then by the law of large numbers, this mean will be very close to the expectation E(X) of the random variable X.
If each outcome is not equally likely, then the arithmetic mean becomes the weighted mean, where each outcome is weighted by its probability of occurring.
Definition
Let X be a discrete random variable assuming the values x_1, x_2, \ldots with corresponding probabilities p_X(x_1), p_X(x_2), \ldots . The expectation (also called expected value or mean) of X is defined by
E(X) = \sum_{n=1}^{\infty} x_{n}\ p_{X}(x_n)provided that the series converges absolutely. In this case we say that X has a finite expectation. If \sum_{n=1}^{\infty} \ \lvert x_n \rvert \ p_X(x_n) diverges, then X has no finite expectation i.e., the expectation of X is undefined. This is because either the series E(X) diverges or its value depends on the order in which the x_ns are listed.
The expected value of a discrete random variable is a weighted average of the possible values that the random variable can take on, weighted by their probabilities.
If anyone is wondering why we are interested in the convergence or divergence of \sum_{n=1}^{\infty} \ \lvert x_n \rvert \ p_X(x_n), let us take a little detour to calculus to answer this question.
Calculus Refresher :
A series \sum_{n=1}^{\infty}a_n is absolutely convergent if the series of absolute values \sum_{n=1}^{\infty}\ \lvert a_n\rvert is convergent.
If a series \sum_{n=1}^{\infty}a_n is absolutely convergent, then it is convergent (the series sums to a single value as n \rightarrow \infty).
A series \sum_{n=1}^{\infty}a_n is conditionally convergent if it is convergent but not absolutely convergent, i.e., if \sum_{n=1}^{\infty}a_n converges but \sum_{n=1}^{\infty}\ \lvert a_n\rvert diverges (the series does not sum to a single value as n \rightarrow \infty).
It is important to know whether a given convergent series is absolutely convergent or conditionally convergent because this determines whether infinite sums behave like finite sums.
Even if we rearrange the order of terms in a finite sum, the value of the sum remains unchanged. But this is not always the case for an infinite series.
By a rearrangement (or permutation) of an infinite series \sum_{n=1}^{\infty}a_n we mean a series obtained by simply changing the order of the terms.
For example, one permutation of \sum_{n=1}^{\infty}a_n , could start as follows:
a_1 + a_2 + a_7 + a_3 + a_4 + a_{13} + a_9 + \ldots It can be proved that if \sum_{n=1}^{\infty}a_n is an absolutely convergent series with sum s, then any rearrangement of \sum_{n=1}^{\infty}a_n has the same sum s.
However, any conditionally convergent series can be rearranged such that the new series either converges to an arbitrary real number or even diverges.
This was proved by Reimann and following is the statement of Riemann’s Rearrangement Theorem:
Let \sum_{n=1}^{\infty}a_n be a conditionally convergent series of real terms, and let S be a given real number. Then there is a rearrangement \sum_{n=1}^{\infty}b_n of \sum_{n=1}^{\infty}a_n such that \sum_{n=1}^{\infty}b_n = S. There also exists a rearrangement \sum_{n=1}^{\infty}b_n such that \sum_{n=1}^{\infty}b_n = \infty . The sum can also be rearranged to diverge to -\infty or to fail to approach any limit, finite or infinite.
Note: I have not proved any of these results. Sometime in the future (when time permits) I might write a detailed note on Sequences and Series with proof of these statements. If you want to go deeper you can refer either to Tom Apostol’s Calculus Volume 1 or for fun and challenge try to prove them yourself. 🙂
Now coming back to our series, E(X) = \sum_{n=1}^{\infty} x_{n}\ p_{X}(x_n), we have three cases :
- The series \sum_{n=1}^{\infty} x_n \ p_X(x_n) diverges. In this case, the expectation E(X) does not exist and is undefined.
- The series \sum_{n=1}^{\infty} x_n \ p_X(x_n) is absolutely convergent (i.e.,\sum_{n=1}^{\infty} \ \lvert x_n \rvert \ p_X(x_n) is convergent). This implies that the expectation E(X) converges and any rearrangement of \sum_{n=1}^{\infty} x_n \ p_X(x_n) has the same sum. So the expectation E(X) exists and is finite.
- The series \sum_{n=1}^{\infty} x_n \ p_X(x_n) is conditionally convergent (i.e., \sum_{n=1}^{\infty} x_n \ p_X(x_n) converges but \sum_{n=1}^{\infty} \ \lvert x_n \rvert \ p_X(x_n) diverges). This implies that terms in the series could be rearranged such that E(X) could either converge to an arbitrary real number or even diverge. Hence the expectation E(X) is undefined.
Some Examples of Expectation Calculation
Expectation of a roll of a fair die
Let X be a discrete random variable that denotes the result of rolling a fair 6-sided die. X can take on any of the values 1, 2, 3, 4, 5, 6 with equal probabilities of \frac{1}{6} . Using the definition, the expected value,
\begin{equation*}
\begin{split}
E(X) & = \sum_{n=1}^{\infty} x_n \ p_X(x_n) \\
& = 1 \cdot \Big(\frac{1}{6}\Big) + 2 \cdot \Big(\frac{1}{6}\Big) + 3 \cdot \Big(\frac{1}{6}\Big) + 4 \cdot \Big(\frac{1}{6}\Big) + 5 \cdot \Big(\frac{1}{6}\Big) + 6 \cdot \Big(\frac{1}{6}\Big) \\
& = \frac{21}{6} \\
& = 3.5.
\end{split}
\end{equation*}It should be noted that the expected value is not one of the possible outcomes; its obvious that we cannot roll a 3.5. 😉 However, if we average the outcomes of a large number of rolls, the result approaches 3.5.
Expectation of profit from the purchase of a raffle ticket
Let us look at an interesting use case. Suppose your city organizes a raffle once a month. A thousand tickets are sold for \$1 each. Each ticket has an equal probability of winning. There are three prizes to be won; namely the first price is \$300, the second prize is \$200 and the third prize is \$100. Sam would like to participate in this monthly raffle. He has two questions he wants to know the answers to which will help him decide whether it is profitable for him to participate in this raffle; namely
- What is the probability of winning any money on the purchase of one ticket?
- If Sam were to participate in this raffle every month, on average how much does he expect to win (or lose)?
With our knowledge of probability let us help him answer these questions. We model this problem by first coming up with a random variable that denotes the profit on the purchase of one ticket and then constructing a probability distribution that assigns specific probabilities to each of the value that random variable can take. We can then answer the questions using the probability distribution of the random variable.
Let X be the discrete random variable that denotes the profit from the purchase of one raffle ticket. X can take any of the values 299, 199, 99, -1 (since \$1 was paid to purchase the ticket, this amount was subtracted from the winnings). The probability distribution of X is given by,
\begin{equation*}
\begin{split}
p_X(299) & = \frac{1}{1000}= 0.001, \\
p_X(199) & = \frac{1}{1000}= 0.001, \\
p_X(99) & = \frac{1}{1000}= 0.001, \\
p_X(-1) & = \frac{997}{1000}= 0.997,
\end{split}
\end{equation*}and p_X(x) = 0 for all other values of x.
Let W be the probability of winning any money on the purchase of one raffle ticket.
\begin{equation*}
\begin{split}
P(W) & = p_X(299) + p_X(199) + p_X(99) \\
& = 0.001 + 0.001 + 0.001 \\
& = 0.003.
\end{split}
\end{equation*}Sam has a 0.3\% chance of winning any money on the purchase of one ticket.
Using the definition of expectation,
\begin{equation*}
\begin{split}
E(X) & = \sum_{n=1}^{4} x_n \ p_X(x_n) \\
& = (299) \cdot (0.001) + (199) \cdot (0.001) + (99) \cdot (0.001) + (-1) \cdot (0.997) \\
& = -0.4.
\end{split}
\end{equation*}
This means that if Sam were to play the raffle repeatedly, then although he might win sporadically, on average he would lose 40 cents per ticket purchased.
Linearity of Expectation
If X and Y are random variables with finite expectations, then the expectation of their sum exists and is the sum of their expectations:
E(X + Y) = E(X) + E(Y)
The random variables X and Y are functions that assign a real number to every outcome s in the sample space. They may also assign the same value to multiple sample outcomes.
If X(s) is the value that X assigns to the outcome s, then
E(X) = \sum_sX(s) \ P\big(\{s\}\big)where P\big(\{s\}\big) is the probability of the outcome s occurring.
Similarly for random variable Y defined on the same sample space S,
E(Y) = \sum_sY(s) \ P\big(\{s\}\big)Using the definition of expectation,
\begin{equation*}
\begin{split}
E(X) + E(Y) & = \sum_{i=1}^{\infty}x_i \ p_X(x_i) \ + \ \sum_{j=1}^{\infty}y_j \ p_Y(y_j) \\
& = \sum_sX(s) \ P\big(\{s\}\big) \ + \ \sum_sY(s) \ P\big(\{s\}\big) \\
& = \sum_s\big(X(s) + Y(s)\big) \ P\big(\{s\}\big) \\
& = \sum_s\big(X+Y\big)(s) \ P\big(\{s\}\big) \\
& = E(X + Y)
\end{split}
\end{equation*}Since X and Y have finite expectations, we know that the series E(X) and E(Y) converge absolutely. So the sum can therefore be rearranged (since an absolutely convergent series sums to the same value even when its terms are rearranged) to \sum_s\big(X(s) + Y(s)\big) \ P\big({s}\big) which by definition is the expectation of X+Y. This proves that E(X+Y) exists.
Note: If f \text{ and } g are two functions, then (f+g)(x) := f(x) + g(x) . The domain of (f+g) is the intersection of the domains of f and g and the range the union of their respective ranges.
The linearity of expectation is true for any number of random variables. If X_1, X_2, \ldots, X_n are random variables numerically summarizing different aspects of a certain experiment, then,
E(X_1 + \dots + X_n) = E(X_1) + \cdots + E(X_n).
Joint Distribution
Individual distributions of two random variables do not provide any information about whether the random variables are independent or dependent. For example, random variables X \text{ and } Y are independent if they indicate Heads on two different coin flips and dependent if they indicate Heads and Tails on two different coin flips. (If X indicates Heads, then Y = 2 - X indicates Tails.) Joint distributions capture information about how multiple random variables interact. Suppose we want to study how stock prices evolve over time, and since there could be a multitude of factors affecting prices and these factors could be interrelated it would be better to study these factors in tandem than in isolation and the joint distribution provides us with a framework for doing this.
The distribution of a single random variable X provides complete information about the probability of X falling into any subset of the real line. Analogously, the joint distribution of two random variables X and Y provides complete information about the probability of the vector (X, Y) falling into any subset of the plane.
As already discussed, since in cryptography we work only with discrete random variables, we will only discuss the joint distribution of discrete random variables.
Definition
Consider two discrete random variables X \text{ and } Y defined on the same sample space S. Let x_1, x_2, \ldots \text{ and } y_1, y_2, \ldots denote the values which they assume, respectively. Also, let the corresponding probability distributions of X \text{ and } Y be p_X(x_i) \text{ and } p_Y(y_j) for i, j = 1, 2, \ldots.
The aggregate of outcomes (of the experiment) in the sample space S for which the two conditions X = x_i \text{ and } Y = y_j are satisfied forms an event (X = x_i, Y = y_j), whose probability is denoted by P(X = x_i, Y = y_j). The function
p_{X, Y}(x_i, y_j) = P(X = x_i, Y = y_j)is called the joint probability distribution (or joint PMF) of X \text{ and } Y.
Like the PMFs of single random variables, the joint PMFs must also be nonnegative and sum to \mathcal{1}, where the sum is taken over all possible values of X \text{ and } Y i.e.,
p_{X,Y}(x_i, y_j) \geq 0 \text{ and } \underset{x_i}{\Sigma } \underset{y_j}{\Sigma} \,p_{X,Y}(x_i, y_j) = 1.The joint PMF of n discrete random variables is defined analogously.
Since the joint PMF describes the probability distribution of (X, Y), we can use it to find the probability of the event (X, Y) \in A, where A is the set of points in the support of (X, Y), by simply summing the joint PMF over A i.e.,
P\big[(X, Y) \in A\big] = \underset{(x, y) \in A}{\sum} P(X = x, Y = y).Marginal Distribution
The joint distribution encodes the marginal distributions i.e., the distributions of each of the individual random variables.
The marginal distribution of X is the probability distribution of X wherein the probability of each value of X is obtained by summing the joint distribution of the random variables X \text{ and } Y over all values of Y corresponding to that particular value of X.
Definition
For discrete random variables X \text{ and } Y, the marginal PMF of X is
p_X(x) = P(X = x) = \sum_y P(X = x, y = y).
That is, for every fixed i,
p_{X, Y}(x_i, y_1) + p_{X, Y}(x_i, y_2) + p_{X, Y}(x_i, y_3) + \cdots = P(X = x_i) = p_X(x_i).The operation of summing over all the possible values of Y in order to convert the joint PMF of X \text{ and } Y into the marginal PMF of X is known as marginalizing out Y.
Similarly, for every fixed j,
p_{X, Y}(x_1, y_j) + p_{X, Y}(x_2, y_j) + p_{X, Y}(x_3, y_j) + \cdots = P(Y = y_j) = p_Y(y_j).Conditional Distribution
The joint distribution also encodes the conditional probability distributions, which describes the probability distribution of a random variable based on the realized values of other random variables.
Suppose we observe the value of X and want to update the distribution of Y to incorporate this information. Since the marginal PMF, P(Y = y), does not incorporate any information about X, we should use a PMF that conditions on the event X = x, where x is the value observed for X. We call this PMF the conditional PMF.
Definition
The conditional distribution (or conditional PMF) of Y given X = x is the updated distribution for Y after observing X = x.
For discrete random variables X \text{ and } Y , the Bayes’ rule relates the conditional probability distribution of Y given X = x to that of X given Y = y as follows:
P (Y = y \,|\, X=x ) = \frac{P(Y=y,X=x)}{P(X=x)} = \frac{P(Y=y) P(X=x \,|\, Y=y)}{P(X=x)}\cdotThis is viewed as a function of y for a fixed x .
The conditional distribution gives us an alternate way to calculate the marginal distribution.
\begin{equation*}
\begin{split}
P(X = x) & = \sum_y P(X = x, Y=y) \\
& = \sum_y P(Y = y) P(X = x | Y = y)
\end{split}
\end{equation*} Independent Random Variables
Discrete random variables X \text{ and } Y are independent if for all x \text{ and } y ,
P(X = x, Y = y) = P(X = x)P(Y = y).
When two discrete random variables are independent, their individual distributions (or marginal distributions) are all we need in order to construct their joint distribution; we can get the joint PMF by multiplying the marginal PMFs. In general the marginal distributions do not determine the joint distributions; otherwise there would be no need for joint distributions.
The independence is also equivalent to the condition
P(Y = y \,|\, X = x) = P(Y = y)
for all x, y such that P(X = x) > 0.
This is because for all x, y such that P(X = x) > 0,
P(Y = y \,|\, X = x) = \frac{P(Y=y,X=x)}{P(X=x)} = \frac{P(X=x) P(Y=y)}{P(X=x)} = P ( Y = y ).The above equation shows that when two random variables are independent, all the conditional PMFs are the same as the marginal PMFs.